This is an archive of past discussions. Do not edit the contents of this page. If you wish to start a new discussion or revive an old one, please do so on the current talk page.
Substantially altered file uploaded over existing file
If an existing file on Commons ist altered substantially, it shouldn't be uploaded over the existing file, but with a new file name. I notice that today, User:Janitoalevic has uploaded a post-Brexit version of File:EU Member states and Candidate countries map.svg which previously included the UK. That's not the way things should be done, and it also distorts the version history of Wikipedia articles on the EU etc., as now this new version is displayed in older versions of the articles that refer to the state before Brexit. I would rectify it myself, but will not have time in the next few hours, so maybe someone could deal with it. Gestumblindi (talk) 14:41, 1 February 2020 (UTC)
As this file is used so many times it is better to override it and upload the historical one as a new file. --GPSLeo (talk) 17:16, 1 February 2020 (UTC)
@Janitoalevic: we usually upload differences that aren't minor as a new file, but in some cases we'd mark the file with {{Current}} and allow it to be updated. For example, constantly replacing images on a bunch of wikis for File:Euro exchange rate to USD.svg wouldn't be practical. This mostly depends on the update rate. For a map of EU member states, that's debatable. It doesn't change that often, but if the people maintaining it prefer {{Current}}, who am I to argue. For something like a company logo or flag though, overwriting with an updated logo or flag is not done. - Alexis Jazzping plz16:26, 2 February 2020 (UTC)
Well, I don't want to fight about this, but there are two sides to this issue. On the one hand, surely it is easier to upload a current version over a file that is widely in use, so the file name doesn't have to be changed in all articles using that file. On the other hand, especially with such a major change as a member state leaving the EU, it destroys the version history of the Wikipedia articles - all older versions of articles on the EU using that file will now show an EU without the UK, too. But I can accept the {{Current}} solution. Gestumblindi (talk) 20:36, 2 February 2020 (UTC)
Greater coat of arms of (Prussian) Osnabrück?
The seal of Osnabrück on a 1921 "emergency money" (notgeld) note.
I had recently come across this image which shows a coat of arms of Osnabrück, Hannover in Prussia during the Weimar period, but when checking the page "Category:Symbols of Osnabrück" I can't find any such image and I am quite familiar with Prussian heraldry and while it's customary to use wild men on Prussian provincial coats of arms, I have never seen it on a Prussian municipal coat of arms. I wanted to request extraction of it at the graphics lab but couldn't find any sources verifying that this coat of arms was actually the municipal coat of arms of Osnabrück in 1921, does anyone by any chance have a source that can verify its official status? --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 21:51, 1 February 2020 (UTC)
It should be the historical (dated 1647) COA of "Kürschneramt Osnabrück" (Osnabrück's Pelletiers' Guild), to be found on a box in Kulturgeschichtliches Museum.[1] --Den man tau (talk) 22:19, 1 February 2020 (UTC)
It appears the license heading and template was inadvertently duplicated upon upload (see original edit). I have removed the duplication. Note that some images may have two different license templates, e.g. {{PD-USGov}} and {{Cc-by-2.0}}. In these cases both templates should be kept, to ensure broadest usability of the file in different jurisdictions. --Animalparty (talk) 01:02, 3 February 2020 (UTC)
Help with details when uploading an image to Commons
What is the best way to provide the source of this image. The photograph is in the thesis https://dspace.library.uvic.ca//handle/1828/2000 while the photo is on page file:///C:/Users/User/Downloads/laycock_k_MA(2).pdf, which is page 171 figure 11?
Also, What is the best form of words to describe justification for the photograph entering the Public Domain when the photograph was taken in 1891 or before (as a person in the photograph died in 1891) and therefore would have entered the Public Domain 120 years later in 2011?BFP1 (talk) 08:30, 1 February 2020 (UTC)
Thanks Jmabel. (how do I reply using a @?). I have uploaded the image using the descriptive way of justifying Public Domain. Hopefully Ogrebot will clean things up. It is a shame I did not know how to use {{PD-old-assumed}}. The experts tell you to use something but don't tell ignoramuses like me how to to use it.BFP1 (talk) 13:15, 2 February 2020 (UTC)
@BFP1: {{Ping|Username}}, {{Reply to|Username}}, {{Reply|Username}}, {{Mention|Username}} all work. If there is one specifically with an @-sign, I don't know it.
If you've addressed the issue raised by the template on the file page, you are allowed to remove that template. - Jmabel ! talk17:53, 2 February 2020 (UTC)
Thanks Jmabel. I managed to work out the way to change the template to {{PD-old-assumed}}. I still have not managed to use the {{Reply to|Username}} template. It seems to require excessive amount of typing (for an elderly incompetent typist) compared with copying and pasting a name.BFP1 (talk) 19:47, 2 February 2020 (UTC)
I think they are. A photo of every member in history is quite useful, especially so if they are tenured, even though most of them might not meet the notability guidelines of a website.--Roy17 (talk) 12:28, 2 February 2020 (UTC)
Most researchers who published are PhD students or even undergrad students, and I believe most of them do not meet our score. But the faculty should be fine.--Ymblanter (talk) 13:24, 2 February 2020 (UTC)
That's an overinterpretation of scope. By "researcher" I mean anyone with the university title of researcher, not any student doing research. Portraits of any published author or an official member of a University department are of realistic educational value, regardless of whether such a photograph is ever likely to be used on Wikipedia. --Fæ (talk) 13:53, 2 February 2020 (UTC)
I would say even a grad student would be in scope if they made a presentation at a major conference. If I am photographing at a major conference, I certainly try to include them. - Jmabel ! talk17:56, 2 February 2020 (UTC)
Almost anything is in scope. Given that we have thousands of images of random, non-notable tourists at public parks or at the beach, the issue is less about the inherent notability of the person(s) depicted than the context the image depicts. A year book portrait photograph of an unremarkable grad student may have little educational value beyond showing what that person's face alone looks like, whereas an image showing an anonymous elementary school student operating a piece of laboratory equipment, or taking part in an activity, would be more realistically useful to illustrate a subject which needs illustrating. A photograph of my butt is educational for what my butt alone looks like, but it's not realistically useful (Probably!). --Animalparty (talk) 01:26, 3 February 2020 (UTC)
They may not all get a Wikipedia page but they are all in-scope with Wikidata. They can create a Wikidata entry and add their image from Wikimedia Commons. Wikimedia Commons isn't just for the English Wikipedia, it also serves Wikidata. The only requirement is a link back to any reliable source linking them to the college or university, preferably the standard faculty/graduate student directory page. Wikidata can also link them to their ResearchGate profiles and other sources of the publications. Of course the university (with the photographer under a work for hire contract) or the photographer would have to release them under a Wikimedia approved license. Here is a typical faculty/graduate student entry at Wikidata Charles M. Lieber 22:28, 3 February 2020 (UTC)
The whole purpose of this photograph is to show the item. Because it's largely flat, and the photo was not taken from a special angle, the photo is similar to a scan of a piece of paper. My question is whether such a photo can be overwritten by a better-quality one that serves the exact same purpose, just like it's appropriate to overwrite poor scans of documents with better ones.--Roy17 (talk) 14:13, 2 February 2020 (UTC)
@Roy17: DO NOT OVERWRITE IN THESE CIRCUMSTANCES. Are you saying that your overwriting photo of the example at left will have User:Sjschen as its author, and a license granted by that person? And that every Wikipedia will implicitly, without a decision on their part (or even visibility that a change has been made), choose your photo over theirs? This is just plain wrong. - Jmabel ! talk18:01, 2 February 2020 (UTC)
+1, I echo Jmabels sentiments and also IMHO overwriting should never be done unless it's to your own photos (and that should only be for cropping purposes), Also Roy you wouldn't be impressed if someone overwrote on of your files with a recent file of theirs would you ? .... I know for a fact I wouldn't. –Davey2010Talk18:18, 2 February 2020 (UTC)
I find it rather useless to keep worse photos of bas-reliefs. Besides, these photos bear very little creativity.--Roy17 (talk) 19:04, 2 February 2020 (UTC)
@Roy17: Useless or not in your opinion, please see Commons:Overwriting existing files. It doesn't matter if other versions are better or worse: having two files on Commons (one from MET under CC-0, the other uploaded by Sjschen under a CC-BY-SA license) is better than one with conflated, conflicting and complicated file edit histories. Don't trample on the good faith works of others. --Animalparty (talk) 00:53, 3 February 2020 (UTC)
@Davey2010: I wouldn't say "only … for cropping purposes". I routinely first upload a photo the way it first came out of my camera, then overwrite with the post-processed version. See, for example, the upload history of File:Seattle - 1001 Westlake Ave N - 01.jpg. But I certainly would not do this to the photo of another contributor here. - Jmabel ! talk01:45, 3 February 2020 (UTC)
Hi Jmabel, My apologies for the above original comment - I made it sound as if you said "overwriting should never be......" when obviously you didn't say that - I wasn't trying at all to twist or put words in your mouth I simply echoed your sentiments and then gave my opinion on it but I realise it didn't come across that way so my apologies for the original comment, (I've since amended it),
Also I do agree that lighting etc can be changed as I've done this with mine and I've also manually rotated some of mine so again a few modifications are fine, Thanks, –Davey2010Talk10:52, 3 February 2020 (UTC)
Revisiting slightly. The example is not a 2D object, so both in terms of copyright and the value of different photographs, multiple similar photographs have a unique value. For those of us that have tried taking high quality or research quality photographs of coins, clay tablets, inscriptions on papyrus or vellum, or highly illuminated manuscripts, the differences in lighting, angle, and arrangement of the object, are all critical and can reveal different aspects of the object. Objects like this which have embossed detail, show very different features when the lighting changes position or colour. Even when the same camera is locked in position on the object, a close-up photograph is significantly changed by slight focus or exposure adjustments. For these reasons simply overwriting older versions is unhelpful, especially if later reusers may want to try digitally synthesizing multiple photographs in order to layer images or research hard to see/read details. --Fæ (talk) 11:28, 3 February 2020 (UTC)
This section is resolved and can be archived. If you disagree, replace this template with your comment. --Roy17 (talk) 17:24, 9 February 2020 (UTC)
Procedure to handle dubious authorship changes by IP users
By patrolling edits sometimes I find edits where IP users changed the author information of a file. In some cases it is easy to see that this was a real fix, but in most cases it is not clear. I think in many cases the uploaded just forgot to login, but as we can not know this I think it would be the best way to undo these edits and notify the author. For this I created a possible message template. Are there general objection to this procedure or suggestions for the template? --GPSLeo (talk) 18:40, 2 February 2020 (UTC)
It depends on what you are talking about. If we are talking about a public domain work that is old, then such edits are no different than those that come from a logged in user. However, if an anonymous contribution is changing the licence or the name of the logged in contributor, than I think that it is best to revert, or at least to contact the original uploader. ℺ Gone Postal (〠✉ • ✍⏿) 09:54, 3 February 2020 (UTC)
Does someone else have the same issue? In Category:Ara?fastcci on some of the images the mark for good videos (FV) appears, though thes are JPEG images, at least the couple of examples I checked. — Speravir– 01:50, 4 February 2020 (UTC)
WikiFranca month
Hi all,
WikiFranca is preparing the 7th edition of its contribution month. This french speaking event is centered around workshops : each participant organizes a thematic session either online or in their town/city. Last year, around 80 such sessions took place in 17 different countries. They were either set in countries where the local wikimedia affiliate is a member of WikiFranca, or in other countries where wikimedians wished to contribute in French. We welcome every contribution : on wikipedia, wikimedia commons, wikidata, wikisource etc.
Please feel free to make suggestions, prefarably in french, on this page.
--Adélaïde Calais WMFr (talk) 10:20, 4 February 2020 (UTC)
Uploading fonts
Apologies if this has been discussed before: I checked Commons talk:File types and phab: but didn't find anything germane.
I propose that we include free fonts with open licenses in Commons. I believe this fits in the scope because 1.) free fonts would support learning about the topics of design and typography, so having the files themselves available for download and editing are clearly useful for those subject areas and 2.) they will support other types of documents that we include, such as PDFs or SVGs that can embed or use style information to call up on certain typefaces.
The MW software supports webfonts and a number of webfonts are available in WM projects. They are mainly used to support the different alphabets that are offered by unicode. It is possible to add more, if there is a reason to do so. But to use them, individual projects need to support the MW extension and the user needs to have webfonts activated in the browser. It is also possible to upload images of fonts to commons ("the quick brown fox jumped... ABCDEFG... 12344..."). You seem to ask for a way to upload and download font files in commons. That would be possible by adding the approbiate extensions to the allowed file formats for upload, but what then? MW has no way to do anything useful with such files? How should a file description page look? MW software has no way "today" to create a file description page for a font file. --C.Suthorn (talk) 04:27, 1 February 2020 (UTC)
@C.Suthorn: Sorry if I'm somehow unclear but yes, I am suggesting that we include fonts as the types of files that we offer on Commons. We don't have do be able to do anything as such anymore than we need to be able to do anything with DJVU files other than show the pages. If we needed to do something in MediaWiki, then the software should be able to display the full set of characters on the download page. —Justin (koavf)❤T☮C☺M☯04:46, 1 February 2020 (UTC)
DJVU can only be displayed at MW because MW contains an interpreter that creates images of the individual pages. There is no such interpreter for fonts (yet). What about meta-data of the fonts? Ligatures? This would be an complex software project. OTOH: There are websites dedicated to fonts and to open fonts. Just like there is OSM as an open street map. --C.Suthorn (talk) 06:35, 1 February 2020 (UTC)
@C.Suthorn: Don't get hung up on DJVU--I think you are getting distracted. There are also places where users can upload photos and videos. My question is do you object in principle or do you think it's an okay idea but there would be just be challenges to implement it? Meta-data can be displayed the exact same as photos. —Justin (koavf)❤T☮C☺M☯06:52, 1 February 2020 (UTC)
If we allow fonts, they could also potentially be used by templatestyles extension in wikimedia wikis (Currently it supports webfonts but doesnt have any websites on the list of allowed websites to get fonts from). Font loading is also one of the more common things that user scripts load from labs or third parties. As we try to discourage user scripts from unnesarily loading third party resources (for privacy reasons), it would be nice if they could load from commons instead. More generally, i think fonts are really useful in creating educational free media, and thus fit well into commons' mission. So i think its a great idea. Bawolff (talk) 11:12, 1 February 2020 (UTC)
Copyright issue if we allow font uploads
Currently we allow such things as {{OFL}}. It is ok for our current use, but the licence disallows distribution of the font all by itself (i.e. when it is decoupled from document/software) if the distribution is commercial. Thus we will need to separate such licences into two categories, licences for imbedded fonts (because we do not want to make a document "non-free" just because of their choice of fonts) and another for the font file all by itself. ℺ Gone Postal (〠✉ • ✍⏿) 06:57, 1 February 2020 (UTC)
Wikimedia 2030 community discussions: Halfway to the conclusions
As I wrote in my last message here, the strategic recommendations for how we can achieve the Wikimedia 2030 vision are available for your final review. There are three weeks left to share your feedback, questions, concerns, and other comments.
These 13 recommendations are the result of more than a year of dedicated work by working groups comprised of volunteers and staff members from all around the world. These recommendations include the core content plus the Principles and the Glossary, which lend important context to this work and highlight the ways that the recommendations are conceptually interlinked. The Narrative of Change offers a summary introduction to the recommendations material. On Meta-Wiki, you can find even more detailed documentation.
Community input has played, and will continue to play, an important role in the shaping of these recommendations. They reflect this and cite community input throughout in footnotes.
In this final community review stage, we're hoping to better understand how you think the recommendations would impact our movement – what benefits and opportunities do you foresee for your community, and why? What challenges or barriers could they pose for you?
After this three-week period, the Core Team will publish a summary report of input from across affiliates, online communities, and other stakeholders for public review before the recommendations are finalized. You can view our updated timeline here as well as an updated FAQ section that addresses topics like the goal of this current period, the various components of the draft recommendations, and what's next in more detail.
Thank you again for taking the time to join us in community conversations, and I look forward to receiving your input. Happy reading!
The colour scheme of the signs (white letters on blue ground) is used by german Deutsche Bahn. You can actually see the name of the station in the foto. It is to fuzzy to read, but the first letter may be S the last g and in the middle a b? --C.Suthorn (talk) 13:52, 12 February 2020 (UTC)
The train has the colour scheme and doors of a german S-Bahn. I am not aware of S-Bahn crossing the border between Bavaria ans Austria. --C.Suthorn (talk) 14:10, 12 February 2020 (UTC)
I made the wrong assumption: I now realise, that I travelled from Innbruck to Munich the fast way and used Interrail travel day for some local travel around Munich.Smiley.toerist (talk) 20:26, 12 February 2020 (UTC)
Sort Videos/Images based on source, similar to Flickr
Currently Category:License review needed (video) has videos of multiple sources distributed randomly in it. It makes license reviewing time consuming for humans. Can we sort them in appropriate categories ? Example : like this edit for a video from Flickr . Facebook videos should be categorized into Category:Facebook videos review needed similarly for other popular sites. Videos from The U.S. Government should be sorted into Category:US government videos review needed. IMO it would be best to categorize these using parameters in the original license review template, these parameters should be added by bots. @MGA73: -- Eatcha (talk) 04:13, 8 February 2020 (UTC)
Indeed! Edits like this is great! Even if it means it will take me longer to empty Category:Flickr videos review needed. When I went to bed there were like 75 videos left to review and when I woke up there was 125! :-D
Reviewing Flickr videos are super easy. It just take a little time to make sure the video is the same. Some videos look alike but have different length or are somehow not the same. What makes it hard is when you come to a new website and have to look around to find out how it works and where the copyright notice may be located. For example it took me 5 minutes to figure out how to find the copyright notice for youtube videos but now I know where it is I can find it in 2 seconds (lol). So I really prefer to work on one source at a time (like Bollywood Hungama, youtube, flickr). And some I skip because I can't figure out Chinese or Russian sites. --MGA73 (talk) 08:12, 8 February 2020 (UTC)
Geolocation (not) missing for two million photos (and counting)
Geolocation present in the filepage but absent in “SDC” (meaning "structured data commons" — plusplusgood!) is being misreported as missing for more than two million photos. And who is supposed to copy all this geolocation data from one to the other? Please say it’s not expected human editors will do it?! If necessary, this should be done by bot, instead of populating a make-work category.
But is it necessary? And what’s the next step? To remove it from the filepage as redundant because it’s now in a “machine readable” format (as if wikitext was scribbled in clay tablets and transmitted by pigeon or smoke sgnals…), making it unavailable to “power users” and available to Big Data?
The files are not being misreported, it is exactly as the category says. The files have local (wikitext) coordinates, but those coordinates are missing from the Structured Data on Commons data. There should be a bot working on this soon, if it isn't already; human editors don't need to process the category. Having the coordinate templates automatically populate a tracking category like this makes the bot task easier and more reliable. Geographic location is a core use-case for structured data. Currently, Commons relies on a complex system of templates, extensions, and wikitext parsing to make coordinate information machine readable. The data's already there, it's just hard to get to: putting it in SDC makes it more available, not less. --AntiCompositeNumber (talk) 15:30, 7 February 2020 (UTC)
The User:BotMultichill is adding coordinates besides to author, license and copyright information. But there are much more metadata, especial all exif information, like exposure. This should all become added with one bot edit per page, to do not spam the page history. --GPSLeo (talk) 18:09, 7 February 2020 (UTC)
Computer armoire and other modern forms of desks (photos)
In the past (2003 to now) I've found ancient forms of desks gradually popping up here in Wikimedia and have been eventually able to illustrate most of the articles I've started in Wikipedia on the topic. I've had no such luck with modern forms like computer armoires, for instance. If I type computer armoire or other variants in Google I get thousands of photos. They're from Web catalogues of vendors and not in the public domain, so unsuitable for use in Wikipedia. Can you suggest some way to find a suitable source? --AlainV (talk) 20:17, 8 February 2020 (UTC)
At risk of sounding blithe: could you get photos yourself? If you're able to go to a furniture store, I doubt they would object to you taking photos - many customers do so. You can also search for appropriately licensed photos on Flickr and use COM:F2C to import them. Pi.1415926535 (talk) 20:26, 8 February 2020 (UTC)
Mmmm, I learned that Barbie had a computer armoire. But I saw no hint of a photo licence filter that you and COM:F2C talk about. --AlainV (talk) 00:47, 9 February 2020 (UTC)
Wait a minute. I tried the wizard without the "import from flickr" choice and I got one of the other 4 pics and uploaded it here with this title: computer armoire desk with shield back chair in front of it or https://commons.wikimedia.org/wiki/File:Computer_armoire_desk_with_shield_back_chair.jpg . I think I got everything right. It's been several years since I've uploaded some of my pics to the Commons and I don't remember what I did then but I have the impression I got it right this time, with the right 2.0 license with its circled little person logo. Thanks for all the help. --AlainV (talk) 13:43, 9 February 2020 (UTC)
Rail transport buffers - pre CFD discussion
I have started a discussion at Category talk:Buffers about a significant reorganisation of the category tree with a view to getting a rough consensus on things before making a formal CFD proposal. Input from those with knowledge of rail transport and/or experience of Commons categorisation schemes would be especially useful but obviously all constructive comments are welcome. Thryduulf (talk) 11:05, 9 February 2020 (UTC)
Map of Russia
I was very surprised to see that the Wikipedia map for Udmurtia depicts Crimea as part of the Russian Federation. (The map used for the Russian Federation depicts Crimea as 'disputed' which, while disappointing Ukrainian loyalists, is probably the best method.)
I understand the map comes from Wikimedia Commons at Map of Russia - Udmurtia.svg. This map has a tag stating: "The boundaries on this map show the de facto situation and do not imply any endorsement or acceptance".
Shouldn't the map show the internationally accepted boundaries? In Political status of Crimea Wikipedia says that "...the majority of international governments continue to regard Crimea as an integral part of Ukraine."
188.163.53.11612:49, 9 February 2020 (UTC)
Commons is quite happy to host maps depicting different points of view. See COM:NPOV for our policy in this area. Each Wikipedia can choose for itself which maps to use, so if you think a Wikipedia is using the wrong map, you can raise this at the relevant Wikipedia. I notice that someone has already done so at en:Talk:Udmurtia. I don't think it would be appropriate to overwrite File:Map of Russia - Udmurtia.svg since this would almost certainly be a controversial change. --bjh21 (talk) 13:14, 9 February 2020 (UTC)
The photographs entered taken in France and Japan have potential issues as freedom of panorama may not apply to these works in those countries. Copyright was not discussed during the voting process. Raising at:
I use Firefox and I get no map at all, just a blank page of light grey. I suppose the folks at OSM are aware of the problem. I'll try again later. It's not the worst problem the world is facing right now, I'd say. :) MartinD (talk) 15:28, 10 February 2020 (UTC)
I get the map. The problem is that, as detailed above, most other images in the area do not show up. It is some months since I used it, but then I often found other useful images. Now I very rarely find any. Dudley Miles (talk) 22:13, 10 February 2020 (UTC)
The photo is from 2012, Crimea was annexed in 2014, so I'd say that that "Ukraine" is correct anyway, but "Crimea" is of course as correct. Sebari– aka Srittau (talk) 10:25, 10 February 2020 (UTC)
Scaling geograph to a worldwide project
Hi. I'm in contact with a developer of Geograph with the idea of scaling the grid square system for the UK and Ireland http://www.geograph.org.uk/ to a worldwide project. Geograph has been enormously productive for the UK and we've benefited from thousands of their photos as a resource. If we could replicate that for the US and everywhere else I'm certain we'd get a boost of photos being uploaded here and people actively trying to fill in weak areas. Even in the US there's so many rural localities and notable buildings without photos. We have a tool Wikishootme which displays dots for images and articles when clicked. Using OSM I was wondering if somebody would be interested in creating a global map within the commons and using the Geograph system to file photos using the coordinates on wikidata to organize them into grid squares worldwide. I think it could potentially help the Wiki Loves Monuments contests too. Is there any support here for this?Dr. Blofeld (talk) 15:08, 10 February 2020 (UTC)
At every other Wikimedia project I have a signature icon in my toolbar, why don't I have one here? Am I missing something in the settings? I have to use four tildes manually. RAN (talk) 01:20, 9 February 2020 (UTC)
Missing from Commons for me. I see it on all other Wikimedia projects. I have to manually add 4 tildes. Is there something in the settings that I screwed up? RAN (talk) 18:23, 9 February 2020 (UTC)
I tried reverting back to default settings and got it back this time, thanks! I think the problem was it wasn't actually going back to default settings in the past, whenever I tried to fix it. --Richard Arthur Norton (1958- ) (talk) 05:04, 11 February 2020 (UTC)
SchlurcherBot
SchlurcherBot is adding "inception" and the date for dated items it finds, wouldn't it be better to be using "point in time" for a photo or a news article? RAN (talk) 17:15, 10 February 2020 (UTC)
It would probably be helpful if you could link to an example of such a change and ping Schlurcher, or even just take this to his talk page. – BMacZero (🗩) 20:04, 10 February 2020 (UTC)
Hi, I am currently removing watermarks (example) and it would be great if I could upload and replace many files in a single move. Commonist doesn't seem to be able to do that, is there a way? Zonderr
You're almost right, I intend to do that an almost automated way. I have already begun, I use the patch-based inpaint filter of G'mic, it is quite fast and easy to use on almost every pictures. Thus at the end, I spend most of my time downloading/uploading. The downloading issue has been solved (see a bit above), if womeone could help for the uploading one, it would be great.
Your picture is a very complex case, it would require much more work, I might not be able to do that one. If you have some easier ones to propose... Zonderr (talk) 14:26, 12 February 2020 (UTC)
"House rules are not copyright. You dont give your copyright just because of some house rules"
Images in category:BoundCon have been taken at the yearly BoundCon event. At https://www.boundcon.com/en/for-visitors/houserules/ the host says: "All images and sound material recorded at the event may only be published with the written consent of the organizer." User:JIP says, he has written consent from the host to publish for non-commercial porposes at commons. User:Tm undid my npd with the resoning houserules are not copyright. Do this files need an OTRS-permission or not? --C.Suthorn (talk) 15:23, 12 February 2020 (UTC)
The problem is that we are an international project and the possible restrictions by house rules are different in very country. This event was in Germany. Here it is allowed to take photos on a private ground without permission if there is a public interest of taking pictures there. But sometimes that gets discussed at court. But I think that does not apply here, because at is just a small convention. --GPSLeo (talk) 16:27, 12 February 2020 (UTC)
I find the Commons "copyright tags" by country extremely useful. So thanks to all involved. I recently went to check on the tags for Gambia and was flummoxed because there were none. I did a search and found a document that covers copyright law dated 2004 and decided it was time I created a tag as I had found all the other tags useful. I see there is a clever system for gathering these tags together which I don't understand. So... is there anyone here who could cast an eye over this draft and tell me if it could be published and what is the right way to do it ... or should I be bold and JFDI? Thanks for listening. Victuallers (talk) 11:40, 12 February 2020 (UTC)
@Kaldari: Thanks (and Fae). I did as you suggested only to find that there IS a tag for Gambia already (%^^%!).... but it doesnt appear in the lists of by country tags. I have clumsily tried to change the template so it does but not sure if this will work as I don't understand the process. Thanks again for the support. Victuallers (talk) 16:15, 12 February 2020 (UTC)
The monitor in #2 was easy to find, but I don't think we have an appropriate category for external video monitors yet. --El Grafo (talk) 12:42, 14 February 2020 (UTC)
Well, Matrixborden would presumably just be "matrix boards" in English, and we do use the term "matrix signal" for some smaller, similar signs. Anyway, I bet we have quite a few photos of this type of sign, and if someone wants to work on categorizing them better, please feel free. - Jmabel ! talk16:24, 14 February 2020 (UTC)
Protection message on pages with template protection
Templates that have a protection level of Template editor currently displays a message "This page is currently semi-protected, and can be edited only by established registered users.", but this is not accurate. The template is not semi-protected and can't in fact be edited even by established, registered users. An example is Template:Taken on. As per the templates protection log, this template can only be edited by admins or template editors: "Allow only template editors and administrators". This message is confusing and wrong, and should be updated to take into account the new user group that was introduced last summer. TommyG (talk) 08:41, 14 February 2020 (UTC)
For a couple of weeks or more, I've been having great difficulty using the Upload Wizard for sets of images - it typically times out at the "select images" stage, sometimes on the first or second lot, even if I only add them 4 for 5 at a time.
I know about Pattypan, but it often not worth using for smaller batches.
I'm finding that multiple concurrent uploads often all fail, whereas consecutive uploads (Add another file) generally work. I'm guessing this is a resource problem. Rodhullandemu (talk) 14:55, 14 February 2020 (UTC)
Sounds like an issue with the rendering engine that Firefox and Pale Moon use (respectively, Gecko and Goanna, a Gecko fork). The other mentioned browsers – Chrome, the newest Edge, and Opera – are based on Chromium and use the Blink engine. If you need to use a Chromium-based browser for mass uploads to work but want something privacy-focused like Firefox, I'd recommend Brave. In a similar vein, if anyone's a fan of Opera but doesn't like the direction the company is heading (see Andy's link above), Vivaldi is a good alternative. clpo13(talk)19:03, 14 February 2020 (UTC)
Look at the upload timestamps from these 1000 files in User:C.Suthorn/liste/7. They are all from the same event. At the time I was not able to upload more than 10 files with the upload wizard. Sometimes only FF worked, sometimes FF not at all, sometimes not windows, but linux, sometimes only iOS. It is the same error since then. It is sporadic, it works for month, than not at all, it works for me, but not for someone else or vice versa. The uploadwizard has severe problems, that have never been solved, instead new features (SDC) been added. --C.Suthorn (talk) 20:06, 14 February 2020 (UTC)
Excessive number of images?
As a spin-off from #Mass DR of sexuality - there are some good points made in the opening statement by User:Prosfilaes. Indeed, there are subjects (he provides the Tower Bridge as an example) where we have literally thousands of images, and many of those are of mediocre quality (but still above the threshold when one can safely nominate them for deletion for quality reasons, e.g. too blurred). Whereas one can argues that some of these mediocre quality images illustrate some aspects (some details, or views from an unusual side) which good quality pictures do not illustrate, one can still safely assume that we have several thousands of images for this topic - I do not want to call them garbage, because people took trouble to go there, take pictures, upload them on Commons etc - but which are unlikely to be useful for any illustrative purposes, and they also clog the directories, if one searches for a reasonable quality image one has to wade through a lot of images which are clearly not qualified (and yes, I know about quality image search, but often I am not looking for a quality image, but for an image illustrating some particular aspect). In relation to this, several questions:
(i) Do we expect that in the future we will run into problems related to hosting of these images (too much space needed, too little money, possibly too low admin to file ratio) or this concern is unreasonable;
(ii) What is the general community sentiment - should we leave this as it is, or should we try to delete (or discourage upload) images which are of relevant subjects but have inferior quality in the situations there are plenty of superior-quality images around;
(iii) I am sure the problem has been discussed before - are there any pointers? Any thoughts that the consensus might have changed or will change?
My motivation here is that I have a lot of images from my travels which are of a reasonable quality but, with a few exceptions probably not at the quality image level; they illustrate notable subjects, and I recently uploaded them a lot, but I would like to understand whether in the future they could be deleted as a result of a quality drive or smth.--Ymblanter (talk) 10:25, 1 February 2020 (UTC)
Hello, there are several things that we should keep in mind:
Commons preserves all media uploaded here, unless absolutely required to delete it. So even when the file is "deleted" it is actually simply not accessible by the public. So there is very little chance of running out of disk space, which can be solved by deleting images.
My approach here is to encourage uploading quality media, and to do my best to do so, rather than discouraging anything. Because, although I can relate to your point, there is a huge difference between not being able to find something due to the amount of media, and being unable to find something because it has been removed or not uploaded in the first place. The first can be resolved by spending a little time, the latter cannot.
I hope that images will not be deleted just because some better quality images appear to illustrage some general topic. Photographs illustrate much more than just their subject area, they illustrate the time of the year in a specific place (when taken outside), year itself, etc. Often media can be used for educational purposes, which cannot be predicted in advance. Of course, I will not go as far as to suggest that we create Category:Photographs taken while forgetting to take a lens cap off by time of the day in January 2020, I can see how somebody may be interested in a selection of photographs based on their metadata alone, or based on their colour scheme. For me the threshhold should remain as "Is the file educationally useful?" and not "Is it more useful than other files already on our system?".
Part of my problem with the Tower Bridge photos, is that we have hundreds of photos illustrating that the Tower Bridge was the same in 2013 as it was 2012 and 2014. There is some difference between not being able to find something due to the amount of media, and being unable to find something because it has been removed or not uploaded, but I think you exaggerate and forget about off-Commons. If I had all the time in the world, I could save up and photograph many modern subjects personally. If I'm blowing past a Wikipedia article and say "we need a photograph of this specific thing here", I may not be willing to spend more than five minutes on it. Moreover, a plethora of low-quality images may cause me to miss the best quality image.--Prosfilaes (talk) 23:23, 1 February 2020 (UTC)
We might have "hundreds of photos illustrating that the Tower Bridge was the same in 2013 as it was 2012 and 2014"; but we might also have users who want a pictue of "a blonde woman in a red dress on tower Bridge"; "a blue Ford Focus on Tower Bridge", "two taxis passing on Tower Bridge", or any other such combination. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits21:24, 7 February 2020 (UTC)
For what reason? It is certainly not in our educational scope to provide all combinations of "two x passing on Tower Bridge". It is also not free to do so; works take time to be categorized and license checked. And it's pretty pointless to search for those, because we don't have them, and won't have them. In the fantasy future, where one can cross Category:Multiple taxis with Category:Tower Bridge, and get something, I can't imagine how many hours will have gone into categorizing photos so that out of the tens or hundreds of thousands of photos of Tower Bridge we'll have, one could find the one they needed. And you know what? They won't, because so many of those hundreds of photos of the Tower Bridge are all the same, taking the same basic photo with changes to weather and slight changes to angle. If they happened to catch "two taxis passing on Tower Bridge", it's not going to be the picture of two taxis passing on Tower Bridge they had in mind; it's more likely to be one that happened to have two taxis in it.--Prosfilaes (talk) 05:56, 10 February 2020 (UTC)
Then you need to re-read the OP, which includes (emboldening mine) "or should we try to delete (or discourage upload) images which are of relevant subjects but have inferior quality in the situations there are plenty of superior-quality images around". Shall we take your apology as read? Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits11:55, 15 February 2020 (UTC)
The social issue for Commons is how we agree to go about curation. Right now the choices are:
Try to get the worst files deleted
Create gallery pages, even though it's unclear how useful they are
Nominate images for Valued or Featured status
These are potential options, but it has always seemed obvious to me that we need to incentivise the Valued Image process. If someone were to go through 100,000 images within a specific topic area or batch upload project, and pick out the top 1000 that are the best from that collection, that's super work that should be rewarded.
How about creating different levels of barnstars for curation (like senior/master/wizard curators?), or start some competitions with some merchandizing thrown at it?
How about creating some use cases for better tools to see VI/FI when using gallery and slideshow tools for categories? If using VI could be a realistic substitute for creating gallery pages, folks might be at least as engaged with that work as they are with deletion requests. --Fæ (talk) 11:58, 1 February 2020 (UTC)
Just the dictionary definition: the action or process of selecting, organizing, and looking after the items in a collection...
Marking the best images so users can easily find them, is one method for us, the other being galleries. Maybe we can come up with easier and smarter workflows, for example the automation of gallery creation using FI/VI status would be a relatively trivial bot job. --Fæ (talk) 12:51, 1 February 2020 (UTC)
I do agree that curation is the largest challenge, and while I was not an early fan of structured data, once I gathered enough caffeine to sit through a few talks on the possibilities...well, the possibilities are promising. There is still an infrastructure problem, and it's not clear that it will be terribly useful in the next two or three years, but once the infrastructure is in place, it should make things a great deal more navigable.
As to sheer number of images, I think a lot of the misunderstanding there, especially from non-Commons users from other projects, is that they've just never really spent a lot of time with traditional archives. If anyone thinks the Library of Congress doesn't have a substantial number of...I dunno...unidentified photos of miscellaneous spoons, then that's a problem with their personal perspective, not with us or with LOC. In that respect, Commons doesn't look all that different once you get the lay of the land of what an archive looks like. GMGtalk12:34, 1 February 2020 (UTC)
But the Library of Congress sucks for our purposes. As a traditional library, I have a more complete collection of (the US published) w:GURPS, and what I have is better cataloged, because it is not something that the Library of Congress cares about, so what they do have is tossed in a box and cataloged in a half-assed manner. If I want to find pictures of miscellaneous spoons, I wouldn't go to the Library of Congress, for the same reason; there are people out there who care much more about spoons and categorizing them. Those LoC collections are useless; unless you live in DC and your time isn't worth much, you should go elsewhere. In those case, the LoC collections are not standards to look up to.--Prosfilaes (talk) 23:23, 1 February 2020 (UTC)
(i) "too much space" won't be an issue. To the degree that's an issue, it has been an issue for years, in the sense that a complete backup of Commons by a third party isn't too realistic. But for Wikimedia? No. No problem, quite simple, though it's a bit complicated to explain. The majority of files on Commons are images, and here we are specifically talking about photos. Photos basically come in two formats: JPEG (1992) and HEIC. (2013) Every other format is so little used it's irrelevant and everything between 1992 and 2013 basically failed for photos. (I'm oversimplifying stuff okay) The patents for HEIC aren't going to expire for well over a decade from now, so #care on that front.
I said all that for only one reason: to say compression isn't a factor and won't be for the upcoming decade. Well, unless AVIF takes off as a native format for cameras, but that's speculation. Something that isn't quite speculation is that megapixels go up. We get more of them, not less. And flash-based storage, which cameras use nowadays, also goes up, so compression ratios don't need to go up. So photos get bigger.
With me so far?
Now skip 10 years into the future. Those old pictures we have are now suddenly tiny compared to what people will be uploading in 10 years. There will be no point in removing any of them. If you are running out of space, what are going to delete first: Video CDs (up to 1.6GB for a movie on two discs), DVDs (typically 6-8GB for a movie), Blu-rays (typically 35-45GB for a movie) or Ultra HD Blu-rays (typically 60-70GB for a movie)[2]? Yeah, you're not gonna bother sorting out your VCDs are you? And I'm actually ignoring the fact here that the WMF doesn't delete anything, because everything (apart from some stuff that's too illegal) can be undeleted.
Too little money? Money equals disk space, same argument.
Too little admin to file ratio? That's not a thing. File count ≠ admin workload. And while there are exceptions for sure, older images have typically already been checked. The majority of admin workload is (I think) directed at new uploads. A shortage of admins is pretty much an ongoing problem, but the people of the future aren't too likely to thank us people of the past for deleting a bunch of images. Also, the actual deletion and sorting out would be a massive undertaking if one wanted to delete a number of images that would have any impact at all. An undertaking so massive we don't have the manpower to do it, not just in terms of admins but also volunteers.
(ii) deletion is out of the question basically. Better categorization, making VI/FPC so it's less broken, those are much more sensible solutions. Discouraging new uploads, well.. if you can do that without also discouraging users from uploading the images we do want, sure, but I wouldn't know how.
(iii) I can't think of any particular discussion right now, but I think I've seen the subject before. And I don't think it ever goes anywhere.
There's also more to photos than meets the eye. Some photo may be of lower quality, but could have a less restrictive license. If I'm creating a derivative work, I'll sometimes avoid CC BY-SA because BY-SA will "upgrade" a collage of 50 public domain images to BY-SA. Similarly, some people will avoid images that have fallen into the public domain in the US but not in Germany or vice versa. And personally I'll also avoid images where the history isn't quite as clear as some alternative with lower quality. Flickr account with one upload and no EXIF or a slightly more blurry photo from an established photographer? I'll take the latter, thanks, and I'll be mortified if that's the one you deleted because its quality was lower! - Alexis Jazzping plz14:34, 1 February 2020 (UTC)
I think we should keep nearly every free licensed image and also say that we want to have many files. But we also should think about methods of curating images that is makes is easier for endusers to find what they want. But for third party services we should serve as many as we can. --GPSLeo (talk) 17:22, 1 February 2020 (UTC)
I don't know what we should do. I'm a bit frustrated that Category:Varnum Building has two images of a historical building in a US town with a hundred thousand people, in a location that maybe five thousand people crossed a day (traffic jams on that street were epic), and they're both after the fire that destroyed it. People often don't see where a photograph would fill our holes, and sometimes it is too late. As GPSLeo implies, discouraging people from uploading photos of the Tower Bridge is not really going to get us photos of interesting, but less heavily photographed, places. Maybe VI/FPC could be better, but I've got the feeling that there's more interest there in pretty pictures than in photos that are useful to Commons.--Prosfilaes (talk) 23:23, 1 February 2020 (UTC)
Well, I do not know. In the town where I live there are several thousands of listed historic buildings, and most of them have zero photographs on Commons. I am using my time on the weekends (when there is good weather, which does not happen too often) to take pictures of those and upload them on Commons. (I see that there is another photographer doing the same, so probably we will have all of them covered in a couple of years). I have a lot of travel photos of places which have encyclopedic notability, or are generally useful, and I upload these, several per day (I even have recently written an essay about this, [3], which is however trivial for Commons regulars). I do not think I am in any way special, may be people just do not realize what the best practices are.--Ymblanter (talk) 23:42, 1 February 2020 (UTC)
This may be why some Wikimedia chapters decide not to participate in Wiki Loves Monuments. Wikimedia Czech Republic shifted its focus to lesser-known monuments in a currently running "Describe a monument" competition which awards wrting new articles. With ~2 weeks left 77 new articles were submitted so far (since January 15). The overlap with Commons may be limited, however. I am not sure how many editors decide to take their own photos. Pinging @Aktron, who may have something to add on this topic.--TFerenczy (talk) 10:59, 2 February 2020 (UTC)
HI! The contest does not focus on Commons. The reason we are doing this with WMCZ is clear: 3 years brought us 25k images of cultural monuments, 25k were probably taken by volunteers in the years after (past 2014). So we have 50k of files of cultual monuments (40k of items are listed by National Heritage Institute) but only a small amount have their own articles. This star difference goes against the logic of our project and that is why we want to balace it. Aktron (talk) 11:04, 2 February 2020 (UTC)
Curation idea
@Prosfilaes, GreenMeansGo, Ymblanter, and Fæ: I've been thinking about new ways to curate files, it hadn't fully taken shape but I just now took the time to write down what my idea roughly is. But maybe you could also share your thoughts on this. I think VI/FPC are not really useful to solve the perceived problem. I would suggest a new "seal of approval" (or completely overhaul VI) where any patroller (possibly even autopatroller) can give a file a "seal of approval". The requirements for that would be something like: its copyright status is beyond reasonable doubt. That would mean a photo from a Commons or Flickr user with only 1 upload and no OTRS won't be eligible. We don't delete such files because AGF, but we have little to go on in such cases. If there's anything else that makes a file suspect, it equally won't be eligible, the threshold for that will be lower than the threshold for starting a DR. In addition it should be among the best files of its kind, which is a bit more loose than the Commons:Valued image criteria. If we have 50 images of the Tower Bridge in the same weather conditions, same time of day, nearly the same angle, there'll be no problem giving 3 or 4 of those the "seal of approval", especially if they have different licenses. Also, photos from different angles can all be given the seal, whereas VI will typically force you to pick one. So Commons:Valued image criteria 1 and 2 are loosened, 3, 4 and 6 would be the same. 5 I would say would be optional, but if missing the file should be categorized into a "location wanted" category or something.
So to sum up: like VI, but any (auto?)patroller would be allowed to tag files without voting. (topic ban for anyone who abuses this or continues to tag files despite getting opposed frequently) Commons:Valued image criteria 1 and 2 are loosened and 5 would be optional. A copyvio check is included (which VI lacks) that found the file to be most likely properly licensed. The exclusions (presentations, audio, video, etc) also won't apply. - Alexis Jazzping plz09:08, 3 February 2020 (UTC)
Well, thinking on terms of getting something for nothing, I think it would be useful to have some metric of a "use factor" built into the "good pictures" drop down menu on categories. There is at some level never going to be any substitute for humans browsing images and selecting which ones are best, but we already have a system in place which does this naturally, specifically, humans from all our sister projects deciding what images to use in their work. Obviously that's not helpful for small categories, but if we look at something like Category:Washington Monument, we have a category with over a thousand images, that has entries on 59 projects, presumably all of which actually use media from this category. So if someone makes a new entry, and sits down to create our missing Wikivoyage page, probably one of the best indicators of what media they might want to use is what images others have already selected to use themselves. GMGtalk12:00, 3 February 2020 (UTC)
@GreenMeansGo: very good point, I was going to mention it (though not so thoroughly) but I forgot. (long rant about QI/VI removed - I realized how unlikely it is to change anytime soon after Rodhullandemu's comment, so let's not waste time) - Alexis Jazzping plz22:03, 3 February 2020 (UTC)
Sorry, if I'm going to walk for miles round the northwest of England in all weathers taking photographs that are better than the ones we have, particularly the Geograph crap, a little recognition warms my heart, improves the quality of my photography and in the absence of financial reward, is all I've got. Any change to VI or QI and I'm out of here. Rodhullandemu (talk) 22:10, 3 February 2020 (UTC)
@Rodhullandemu: hmmmm, point taken, but that doesn't make VI useful for finding useful media. I guess this is one of those things that'll never really change. You'd still be able to move the "new VI" from that lowres Geograph image to your own photo and apply for QI, but if that isn't enough, I guess we'll have to stick with what we have. - Alexis Jazzping plz22:16, 3 February 2020 (UTC)
@Rodhullandemu: so you won't mind if we remove VI and QI from Help:FastCCI? Because that's the main gripe here I think. FastCCI presents VI and QI as a way of finding good images, and that doesn't work at all. - Alexis Jazzping plz10:40, 4 February 2020 (UTC)
Concerning the usage, I noticed that many articles, especially on the smaller projects, use the same photo which either one of the bigger projects already uses, or use the photo which is on Wikidata (and often these two are the same). People rarely go to Commons to search for better images.--Ymblanter (talk) 09:41, 4 February 2020 (UTC)
Many articles are created by translating an existing (mostly the english (6mill articles!)) article. With the content translation tool the images are taken to the translated article without a choice of other images. Translating without the tool will often have the same result. --C.Suthorn (talk) 02:43, 8 February 2020 (UTC)
Now, concerning the general suggestion, if I get it right, it is to create a new layer of images between QI and nothing, similarly to how many Wikipedias have recommended articles, a layer below GA. It might work, though I see some immediate issues (and there are probably way more, but we are discussing it at the level of an idea):
Indeed, there must be no doubts about the license status of an image (including freedom of panorama, a concept even many experienced users have problems with) and the scope;
The suggestion to assign the status without any discussion, by a select group of users seems reasonable. It should be also some procedure to demote such an image, and I guess the discussion would not be needed either;
My main problem is that users have vastly different standards as far as quality is concerned. Some would say that chromatic aberrations at the periphery make an image such garbage that we should be ashamed showing it; others would not mind having geometric distortions or even blurring. This can cause warring for assigning the status, and generally must be somehow regulated, but I am not sure what would be the best way to do it.--Ymblanter (talk) 11:29, 4 February 2020 (UTC)
Don't worry about deletion to save the Wikimedia Foundation from using space, because we do not delete images. We just no longer display them. 22:39, 3 February 2020 (UTC)
I also really want a new way for curating images. I think the most important thing is that this dose not work with wikitext templates, becaus they can not be used in the standard search. Maybe we make three different types: preferred, discouraged and unassessed. This information should then be stored in the page metadata. --GPSLeo (talk) 14:51, 4 February 2020 (UTC)
This edit brought to my attention that {{int:filedescr}} is not any longer transcluding the word "Summary" in the current UI language. This was a recent change, when did it happen exactly?, and why? Wouldn’t it be better to have a bot replacing it it with the (now) correct {{int:filedesc}} instead of adding it to what has become useless? (I understand why the bot is doing what it’s doing, but it is still wrong — @Schlurcher: ping!) What about keeping both, any of them redirecting to the other? -- Tuválkin✉✇17:58, 14 February 2020 (UTC)
Are we sure it ever worked? Normally these things are defined in code, but I can't find any references to filedescr ever being a thing and the phrase only appears on 4 images at commons. Maybe it was just a typo. Bawolff (talk) 23:12, 14 February 2020 (UTC)
The user who uploaded the image made the typo, so my bot did not realize the heading and added the appropriate one. As there might be lots of different ways to misspell this template, I think there is not much I can do. --Schlurcher (talk) 13:54, 15 February 2020 (UTC)
Wikimedia 2030 community discussions: Last week begins
We are entering the last lap of the discussions on the Wikimedia 2030 strategic recommendations. Until next Friday, February 21, you can share your feedback, questions, concerns, and other comments.
In my last 2 messages on this village pump, I described how the recommendations were created, the role of your input, and the next steps. This time, let me describe just one selected recommendation, one that sounds to be particularly close to the activities on wiki: 'Improve User Experience'.
It states that anyone, irrespectively from their gender, culture, technological background, or physical and mental abilities, should enjoy a fluid, effective, and positive experience during both the consultation and contribution to knowledge. This recommendation is, among others, about the design improvements, user interface, but also training and support programsdedicated resources for newcomers, and, what I personally find especially interesting, mechanisms that allow finding peers with specific interests, roles, and objectives along with communication channels to interact and collaborate.
Please comment on the recommendations' talk pages. What do you think about this and other recommendations? Should some points be improved, removed, or added?
If something is not clear, please ping me. I will write back as soon as I can.
This isn't a productive comment either, but based on the illustrations for the 'recommendations' why are Wikimedians always fat white guys who use expensive Apple iMac's to look at Wikipedia? --Fæ (talk) 19:21, 15 February 2020 (UTC)
Good question. I don't know! This isn't a productive response either, but thankfully, I'm skinny and don't have any Apple device :D But jokes aside, @Bawolff and Fæ: do you have productive comments, like you believe something important related to the UX (user experience) was missed? Keep in mind this is the strategy, so we're talking about visionary thinking now. SGrabarczuk (WMF) (talk) 21:08, 15 February 2020 (UTC)
@SGrabarczuk (WMF): I have mentioned this many times before, but WMF employees seem to really love using the word "collaborate", probably because it's super popular in American English. As no doubt you are personally aware, this word has historic negative overtones in Europe (thanks Nazi collaborators), and when talking to an international community it is easily replaced with phrases like working collegially or even plainer English like "working together".
If the word "collaborate" or variations are built into the recommendations, do let me know so I can keep on raising this where it's in use, even if the chance of being heard is very low. Thanks! --Fæ (talk) 19:54, 15 February 2020 (UTC)
Thanks, @Fæ: yes, I'm well aware of that issue in my language. I didn't know it's the case in other languages, though. FYI, I'm not a WMF employee, and those who wrote these recommendations aren't WMF employees either. I'll report your feedback, and we'll see what the result will be. SGrabarczuk (WMF) (talk) 21:08, 15 February 2020 (UTC)
I am a german nativ speaker and would say that we use the term "collabroative work"(kolaboratives arbeiten) and do not accociate it with anything negative. But the "community leader" term is definitly problematic. --GPSLeo (talk) 21:15, 15 February 2020 (UTC)
I made a clumsy visual representation of the connections between the recommendations (data taken from the sections called Connection to other recommendations). I didn't take into account the cases when a recommendation is connected to all the others. Anyway, I leave making the conclusions to you. In addition, I'm sharing a cloud with the most frequently used words in the recommendations. SGrabarczuk (WMF) (talk) 23:54, 15 February 2020 (UTC)
cross wiki upload with 40 categories (including body modification in Iran, Myanmar, Ivory Coast, Nepla, Indonesia, Afghanistan) does not ring an alarm bell for being somewhat questionabel?
(not the first time the user did something like that) and no bot, filter, mechanism or vandal hunter takes notice?????? --C.Suthorn (talk) 19:06, 15 February 2020 (UTC)
Implicitly this is a complaint about the uploads from @M-Spanky: . It's a courtesy to let them know.
The uploads seem spammy, but the rationale for deletion is because copyright looks super weak. Where published on YouTube, there is no suitable license, so a better statement is needed. If M-Spanky wants to improve commons with images of body art, that's super, but copyright has to be clear. --Fæ (talk) 19:17, 15 February 2020 (UTC)
The uploads seem spammy because they are spammy. The same user was previously blocked as MasterSpanky. Abdo4 is the same person. These images should all be deleted as advertising and the pages created on Wikipedia cleaned up. World's Lamest Critic (talk) 05:09, 16 February 2020 (UTC)
From my side this is neither about copyright or a specific user. It is about UI, Categories, consistency: It is complicated to choose categories in MW, and it is strange if such many categories are attached to a file. Also categories are contradictory. There could (and should?) be a bot and/or filter and/or mechanism in the MW software that notifies (by a category or else) if something like this happens, as it will probalby need manual correction in some way. --C.Suthorn (talk) 06:22, 16 February 2020 (UTC)
Based on its name, Category:Leuke kome should contain files related to a settlement called Leuke Kome. The category is however entire made up of regional maps that show Leuke Kome as just another among many other places. How appropriate is it to categorise such zoomed-out maps according to the places they show? If appropriate, I foresee a very long list of categories for each map. --HyperGaruda (talk) 06:23, 16 February 2020 (UTC)
I am not sure why the maps were placed int this category. There may exist some special reason. The maps are historical after all. Otherwise maps should not be placed into settlement categories. Ruslik (talk) 20:22, 16 February 2020 (UTC)
Hello, on looking at File:Dharmaraya Swamy Temple Bangalore edit1.jpg on the en.wiki main page today I couldn't believe the full image was going to be detailed enough for a featured picture. It is, but the lighting is incredibly dull. Also it could stand a slight anti-clockwise rotation. I did not expect to be able to upload a new version while it was on a main page, but the upload system let me try. It failed after the upload, however it said I could request an administrator to do the upload at Commons:Requested updates to protected images. That page doesn't get a lot of response. I have edited a version of the picture in GIMP which ups the brightness and contrast by 30% each, rotates it about 0.45% anti clockwise, and balances a cropping out of the lamppost on the right hand side, and cropped just a sliver off the bottom and left to balance the framing... It's a very minor edit which is unlikely to be questioned usually, but it would be best done today while it is on the main page..? Anyone fancy doing it? I propose this alternative: File:Proposed edit to Dharmaraya Swamy Temple Bangalore edit1133.jpg~ R.T.G11:14, 16 February 2020 (UTC)
I don't understand... I did edit one very small part of the picture... I didn't expect it would be noticeable.. however what you have stated here, overall, I have only changed the brightness and contrast and smudged one tiny piece of it... I've cut out the lamppost. The elements I chopped out had no significant detail except a lamppost? ~ R.T.G11:52, 16 February 2020 (UTC)
Well it's not very important but the picture definitely looks very dull on the main page and has to be zoomed in to full size just to see that it is in fact the processing rather than the scene which is lacking. ~ R.T.G11:53, 16 February 2020 (UTC)
Agree that the photo is dull in tone and annoyingly skewed. However this VP is not the right audience to have an effect on what happens on the en.wp main page. --Fæ (talk) 12:40, 16 February 2020 (UTC)
Best practices for the New York Times archive
What are the best practices for the New York Times archive that is in the public domain? Should we store the pdf file or the jpg/png version? Should we trim off the copyfraud notice or leave it on? --Richard Arthur Norton (1958- ) (talk) 18:44, 17 February 2020 (UTC)
I don't think there are any best practices on Commons for any textual archives. There is some guidance at File types: Textual formats, Project scope: PDF and DjVu formats and Help:DjVu. For indexing public domain sources on Wikisource, see s:Help:Digitising texts and images for Wikisource (I believe they prefer complete magazine/issue/book uploads, from which individual articles can be gleaned, rather than isolated clippings). In my opinion, if a scanned image has reliable source info in metadata (i.e. file description), there is no valid reason to keep the New York Times notice: the articles are public domain, the notice is simply tangential and misleading noise irrelevant to the text. --Animalparty (talk) 19:59, 17 February 2020 (UTC)
Disable pre-2011 "wg" JavaScript variables
Hi,
Almost ten years ago (in 2011), the mw.config.get mechanism was introduced in MediaWiki's JavaScript runtime. This replaced the old way of accessing site information from MediaWiki, where each piece of information was its own global variable mixed in with all other programs bindings and variables. The new way grouped them together to occupy only a single variable, the mwbinding. The example below illustrates what the new code looks like vs the old:
To find out if a gadget or user script that you use is affected by this change, open the JavaScript console in your browser. If you see warnings like "Use of "wgPageName" is deprecated. Use mw.config instead.", then a script or gadget you are using might stop working soon. If you know which gadget is responsible, report it to its talk page. Otherwise, ask for help by commenting below, or at Commons:Village pump/Technical, or reach out to T72470 on Phabricator. See also these Search results which show that some site-wide scripts might be affected, although it's possible some of these are already broken and/or no longer used. I've already started to go through some of these myself.
I'd like to propose for Wikimedia Commons to be one of the earlier wikis to try disabling this compatibility feature so that we can find out sooner rather than later what we need to fix. During this time it will be easy to get us switched back if something is broken, even if the affected script is not very important overall. This will be more difficult if we wait! --Krinkle23:19, 17 February 2020 (UTC)
I have cleared the cache: no change. I am using Safari -does other Safari users here experience the same problem? Huldra (talk) 20:29, 17 February 2020 (UTC)
I have only just discovered that Commons has a DATA namespace for storing structured data. Since structured data is not a media file, I can't figure out how this squares with COM:SCOPE, but I am sure it must have been discussed before. I haven't been able to find one (but that might be because the phrase "structured data" is used to refer to Wikidata quite a bit. Can someone point me to previous discussions or explain how structured data is within Commons scope? Thanks. World's Lamest Critic (talk) 04:25, 11 February 2020 (UTC)
Just for understanding: Did you find Commons:Data with its several links? Note that the term „structured data” is in some kind ambiguous and is usually not used for the data in Data: namespace. Regarding project scope: It would probably belong into an own section or subpage, the .map and .tab have to be JSON files, though. But, yes, apparently this is missing. — Speravir– 18:23, 11 February 2020 (UTC)
@Speravir: I think I followed every link about the DATA namespace on that page. If you think one of the links answers my question about how this aligns with COM:SCOPE, please just tell me where to look. World's Lamest Critic (talk) 03:40, 12 February 2020 (UTC)
Really not that important anymore: The link Keegan gave you can be found from there … My (apparently wrong) expectation was if you was on COM:Data you already would have found this yourself and would have asked for more information. — Speravir– 17:29, 12 February 2020 (UTC)
@Keegan (WMF): Thanks. I see several people opposed this namespace here because it was out of scope for Commons. Strictly counting votes, 28 users supported this and 10 users opposed it. So out of all the users on Commons, 38 of them expressed an opinion. I don't understand how this namespace got added with such little discussion, especially when the scope issue is unresolved. Can you explain? World's Lamest Critic (talk) 21:53, 11 February 2020 (UTC)
@World's Lamest Critic: It seems that Yurik considered that discussion as adequate endorsement and implemented it. Perhaps he could comment further. You're correct that the scope issue has never been resolved, however. I suppose at this point it's a moot issue and we should just add the Data namespace to COM:SCOPE. Alternately, you could propose removing the Data namespace from Commons under the argument that it doesn't conform to COM:SCOPE, but I don't imagine that such a proposal would achieve any level of consensus. Kaldari (talk) 16:01, 12 February 2020 (UTC)
Why would this be a "moot issue"? When it was discussed, users pointed out that it did not belong on Commons because it was outside the scope of Commons. I don't know how @Yurik: could ignore that, but it's not too late to put it somewhere else, since it seems to have been pretty much ignored until just now. You work for the WMF, don't you? What's your role there? World's Lamest Critic (talk) 21:04, 12 February 2020 (UTC)
@World's Lamest Critic: I just meant it's a moot issue because the Data namespace seems to have become more or less accepted. I don't personally have any opinion about that and you're welcome to start nominating those pages for deletion if you like, but I imagine it would be hard to build consensus to delete them. Regardless, I agree with you that our scope guidelines need to match what we actually host. FYI, Yurik used to work for the WMF several years ago, but doesn't currently. Kaldari (talk) 05:50, 16 February 2020 (UTC)
Yes, I'm a director of engineering. I didn't have anything to do with the Data namespace though. Around here I'm mostly just a volunteer admin (which predates my employment at the WMF). Kaldari (talk) 04:56, 19 February 2020 (UTC)
I have no opinion or idea of the history; I had the links handy in a tab as I was just talking to someone about the Data namespace the other day and you asked to be pointed to a previous discussion Keegan (WMF) (talk) 17:05, 12 February 2020 (UTC)
BTW: Only some threads away in #Our World In DataFæ pointed to some other issues. The missing ability to categorise the datasets is IMHO a quite huge one (and do not let us think about adding ability for structured data like for media files). — Speravir– 17:39, 12 February 2020 (UTC)
we have been uploading all the available charts from https://ourworldindata.org/about in SVG format. These maps and charts are deliberately released to help a better public understanding of publicly available statistics about world issues including health, population and poverty.
Where possible the underpinning data has been uploaded in Commons Data namespace as tables, there are currently 380 of them. Refer to the project page. All charts are listed at Category:Our World In Data.
Selected example charts
Deaths from air pollution
Sulphur dioxide emissions by region
Tobacco production
Population growth against age
Alcohol consumption by type in Italy
If the transparent hatched background of the chart is diverting, remember to click on the image on the Commons image page to show it with a white blank background. As standard, the images are shown with different size options for PNG versions, and you may find those more usable. You can edit the SVG file directly using a text editor if you download it first. Refer to Help:SVG for suggestions about tools and other options.
The charts are likely to be helpful in illustrating Wikipedia articles, and volunteers may want to try creating new charts and new maps based on the datasets uploaded, for example by creating versions of maps with country names changed to more "mappable" country codes. Thanks to Doc James for the initial suggestion for this project and several others joining by email to get this underway.
One unintended consequence has been to test out the usability of the Commons Data namespace, some of the bugs and issues are on the project page, in addition to the common frustration of being unable to categorise datasets and their highly restricted JSON format. Users playing around with the datasets may have further suggestions on how to make the data namespace more usable. --Fæ (talk) 17:18, 11 February 2020 (UTC)
The SVGs are still uploading, one every 12 seconds at the moment!
I see a few being skipped as the way filenames are generated based on titles is not smart enough to handle variations, but it looks like a rare naming conflict which can be worked on for a later run.
Update as my unreliable broadband dropped out last night, added some code to handle duplicate titles and restarted the run this morning. There's over 2,000 SVGs and the remaining 1,000 or so to come.
@Doc James: checking https://ourworldindata.org/charts shows that there are lots of duplicated links, probably because the page is divided in to topics and a chart may be relevant to more than one topic. Consequently, there are 2,701 links to unique charts rather than over 3,000. --Fæ (talk) 12:00, 12 February 2020 (UTC)
The missing charts seem to be those with the words "with autism" in the titles, which unfortunately is blacklisted; e.g. File:Share of the population with autism, OWID.svg. These missing files are probably best uploaded manually rather than spending time trying to adapt the batch upload. --Fæ (talk) 18:32, 12 February 2020 (UTC)
@Fæ: Just FYI, for "Description must be under a certain string length, arbitrarily this has been cut off at 241 characters in the absence of a specification" - Code seems to indicate the limit is 400 unicode code points (Why that limit is there, I have no idea. Seems super arbitrary and rather short for a description field). Bawolff (talk) 11:05, 18 February 2020 (UTC)
Thanks. Could someone add that to the MediaWiki summary where future projects can find it? Debugging this upload was made twice as long due to the amount of trial and error involved, bumping into constraints that were not explained anywhere, nor are they based on any external standard for JSON. --Fæ (talk) 11:13, 18 February 2020 (UTC)
It is important to keep a critical eye on dates. Some dates of picture taken are misleading, certainly with old postcards. The exact date is unclear. I cant read the writen date.Smiley.toerist (talk) 23:26, 20 February 2020 (UTC)
Is plantillustrations.org a source of Public Domain images
I have used countless images from the above source for illustrating articles. User:Pigsonthewing is questioning the validity of the site's claim that it hosts only Public Domain material. Could I have a ruling on this please. cheers Paul venter (talk) 14:58, 12 February 2020 (UTC)
Their About page states: All available HD illustrations belong to the public domain according to the European law and may be reused under the Creative Commons License. Please visit the website of the original contributors for further details by using the links provided on the illustration pages." This may not always be clear from the link on Commons file descriptions: File:Parsonsia alboflavescens 123145.jpg links to http://plantillustrations.org/illustration.php?id_illustration=123145, which, at the page bottom, links to the Internet Archive scan, where the original image can be found, i.e. here. So the short answer is yes, for illustrations. However, photographs on the site appear to not be free, as they require contacting the site admins to request permission. --Animalparty (talk) 19:22, 12 February 2020 (UTC)
@Animalparty: And you're prepared to take the word of every third-party site that claims its hosted content is PD? And if the images all "belong to the public domain according to the European law", then why must "the Creative Commons License" be used? Which one? Alarm bells should already be ringing at such bogosity.
Yes, the site is a source of Public Domain images, as your solitary example shows, but not all of its image are PD. Let's look at the works in question:
File:Strychnos madagascariensis02.jpg was recently deleted by as a copyvio, by User:Túrelio, after I tagged it as such. It was apparently published in 1984, and there was "no evidence that creator died >70 years ago".
The creator of File:Cadaba aphylla00.jpg died in 1973. Paul venter believes it is {{PD-old-70-1923}}, and has removed the copyvio tag I added, saying "The plate is from Rudolf Marloth's Flora of South Africa, a volume which he wrote and for which HE commissioned artwork which became HIS copyright. The PD-old-70-1923 permission therefore applies since Marloth died in 1931.". The linked page at plantillustrations.org currently shows no image.
The named creator of File:Crassula perfoliata00.jpg died in 1967. Paul venter removed the copyvio tag I added, and added{{PD-South-Africa}}, whose only clause for non-anonymous/ pseudonymous artworks is "It is ... created under the direction of the state or an international organization and 50 years have passed since the year the work was published." The linked page at plantillustrations.org currently shows no image, and caries the text "Copyright reserved".
In the light of 3 and 4, and Paul venter's note on my talk page telling me to "kindly make sure of your facts before causing more trouble", perhaps this belongs on the admin noticeboard. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits19:41, 12 February 2020 (UTC)
@Pigsonthewing: And you're prepared to make snide, sweeping generalizations based on a single event? I figured there would be exceptions, and of course, no third party source should be taken completely at face value or as an authority when alternative sources conflict. This goes for Internet Archive files posted Flickr Commons, some of which are erroneously "public domain" because someone mislabeled a journal with the wrong date. Many third party sources understandably use the Public Domain guidelines of the country they dwell in, unlike Commons' more restrictive demand that all content must be free in every jurisdiction. When plantillustrations.org provides links, or even text citations, those sources should be investigated to ascertain status if in doubt. We can and should use our brains. --Animalparty (talk) 20:02, 12 February 2020 (UTC)
"snide, sweeping generalizations"? Where? You were quite happy to answer the OP's question with "So the short answer is yes, for illustrations", making no mention of the exceptions you claim to anticipate, and to uncritically quote plantillustrations.org's farcical prose. And this from someone whose user page says they are a "licence reviewer"... Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits20:09, 12 February 2020 (UTC)
Point of clarification: Commons requires media to be free in the US and in the country of origin, not in every jurisdiction (per COM:L#Interaction of US and non-US copyright law). Strictly speaking, Commons could probably get away with only requiring things to be free in the US, since that's where the servers are hosted (just as websites hosted outside of the US need only abide by the laws of their respective countries), but the additional requirements are to ensure files are maximally reusable. clpo13(talk)20:17, 12 February 2020 (UTC)
In view of the conflicting opinions expressed above I feel that the discussion should be taken up a level or more in order to solicit views from more experienced and knowledgeable Wiki users. Paul venter (talk) 13:43, 14 February 2020 (UTC)
There is no real conflict of opinions. I wrote inaccurately, and overlooked the outliers which are causing controversy. plantillustrations.org is not the arbiter of Commons policy, and what is public domain in their jurisdiction may not be public domain in the work's country of origin, and thus not be acceptable for hosting on Commons. See Interaction of US and non-US copyright law. Claims to public domain require sufficient evidence. When clearly observable facts (e.g. death date of artist, date and country of publication) contradict third-party claims to public domain status, in the absence of compelling counterclaims, we can use our judgement remove them from Commons. --Animalparty (talk) 18:37, 15 February 2020 (UTC)
There's no point edit-warring over a copyvio template. The next step should always be to go to a DR. The VP does not establish precedent either way, it's just a chat. --Fæ (talk) 10:14, 19 February 2020 (UTC)
The {{Copyvio}} template says "l: If you think that the file does not meet the criteria for speedy deletion, please open a regular deletion request and remove this template. ". Why, then, is it OK for Paul venter to remove the template without stating a DR, and without adding any template that correctly justifies the file's inclusion on Commons? Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits10:08, 20 February 2020 (UTC)
Anyone can remove speedy tags, once. Anyone can instead escalate to a DR if they are unhappy with the speedy tag, or wish to escalate after removal. As folks will have different understandings of what is sufficient to validate copyright, a DR is always the higher path and, in my view, is highly preferable as such discussions can establish good precedent for other files with similar issues.
Repeatedly removing speedy tags on the same file, or re-applying them after removal, will look like edit-warring regardless of who is "right" about copyright. --Fæ (talk) 10:18, 20 February 2020 (UTC)
I don't dispute that "anyone can remove speedy tags". However, anyone doing so is supposed, according to the template itself, to start a DR. Is that correct, or not? If not, then the template text should be modified accordingly. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits16:09, 20 February 2020 (UTC)
Well, look who just added a template to that effect. Your comment does not reflect the state of the image page at the time I made my above post, when, again as stated above, Paul venter had applied only {tl|PD-South-Africa}}, whose only clause for non-anonymous/ pseudonymous artworks is "It is ... created under the direction of the state or an international organization and 50 years have passed since the year the work was published.". The creator died, according to the file description and as stated above, in 1967, not 1956. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits10:08, 20 February 2020 (UTC)
PD-South-Africa says "It is another kind of work, and 50 years have passed since the year of death of the author (or last-surviving author)." It's not perfectly clear, but why would you object to me fixing it? Something that's PD is not falsely labeled as PD because someone put the wrong template on it.--Prosfilaes (talk) 22:21, 21 February 2020 (UTC)
US Aerial imagery
I found this imagery I'd like to upload on commons that I'd like to upload to Commons. The article claims, that the image was created by US armed forces which would imply that it's PD as of Template:PD-USGov. Nonetheless i can't find any US-american source. Is it possible to upload the image grabed from the german newspaper? -- Dr.üsenfieber (talk) 12:44, 18 February 2020 (UTC)
Competition running until Sunday to improve information about GLAMs
Hi all
Wikimedia Sweden is running a competition running till Sunday to improve coverage of GLAMs (galleries, libraries, archives and museums) on Wikidata, including adding images, it includes much improved instructions for learning how to contribute to Wikidata so its a great opportunity to try Wikidata for the first time.
My user page (In the name of pislam) removed by Achim55
It was about brutality of ISIS in the west, killing of innocent Americans by jihadi terrorists. Why can't I criticize ISIS ? Is criticism of ISIS a valid reason for deletion of my article. -- In the name of pislam (talk) 17:53, 21 February 2020 (UTC)
No, it wasn't criticising but insulting/offending - as your username is. In addition, this is not Wikipedia: Here are no article pages at all --Achim (talk) 17:58, 21 February 2020 (UTC)
You can call it insult but for me it's criticism. Criticism of terrorists is not something that's should offend everyone, are you offended ? Why do you think I should not insult ISIS ? I know it's not Wikipedia but wikimedia commons. In the name of pislam (talk) 18:11, 21 February 2020 (UTC)
You are not required to be afraid, but why are offended? What if I upload a protest poster that reads Fuck Islamic extremists, would you still try to censor it by claiming I am insulting terrorists who are responsible for killing and raping thousands of people ? -- In the name of pislam (talk) 18:22, 21 February 2020 (UTC)
Namely inserting a full-stop after the bracket (before the word 'Signed'). So far it has been declined. Can this correction be made?BFP1 (talk) 08:35, 19 February 2020 (UTC)
Criterion #1 is possible and requests coming from the original uploader are usually not declined. As a file mover I would be happy if uploaders who want to rename files they have uploaded themselves would always choose criterion #1 even if other criteria may seem to fit too. --Andreas Stiasny (talk) 17:10, 19 February 2020 (UTC)
@BFP1: I am sorry that I was one of the people who declined, but you first requested the rename according to criterion 6 (“Non-controversial maintenance and bug fixes”), while this request was clearly not maintenance or a bug fix. Then you requested renaming according to criterion 3 (“To correct obvious errors in filenames”) which is wrong, too: This single period does not count as error. If I had noticed that you have been the uploader I would have done the rename, as well. BTW: Strictly speaking also for uploaders the content of Which files should not be renamed? is valid, but the filemovers are in general quite accommodating if an uploader requests a rename. — Speravir– 22:25, 22 February 2020 (UTC)
Predefined catscan queries not working on a couple of categories
Is there a way to remove link spam by a bot? When you search for the string "Visit our website: www.milescontinental.co.nz", you'll get a lot of results. Professional photos; there's nothing wrong with those. But linking from each photo to their website and Facebook is obviously a misuse of Commons. Please ping me with relevant replies. Schwede6618:25, 23 February 2020 (UTC)
Use the standard search to list affected files, something like "Visit our website insource:www.milescontinental.co.nz" might do it. I see 22 files total.
Click on "Perform batch task" (left hand side of the page in the toolbar) when on the results page, and changing the matched text or blanking it is fairly easy. See Help:VFC and you may need to set it up first per Help:VisualFileChange.js#Step_0:_How_to_Install. Work out how to use the tool and you will be able to do lots of other interesting stuff for the project.
We (the Commons app team) are hoping to release a Commons iOS app this year - we have received quite a few requests for it, so we have included it in our Project Grant proposal for the 2020 PG round. To summarize the rather long proposal, the first release of the iOS app would include complete upload functionality, with the same tutorials/warnings/checks as the Android app currently has, in order to keep the deletion rate low; after that, we plan to start adding some of the more popular features from the Android app, e.g. nearby places that need photos. We also intend to continue supporting our Android users by further polishing and stabilizing the Android app, as well as developing a couple of new features for it.
If this sounds useful or interesting to you, please do take a look at our proposal, and endorse it if you see fit. Or if you have any questions or concerns, please feel free to post in the discussion page. We want to be sure that our plans serve the Commons community well, so your feedback is greatly appreciated.
The w:GDPR is a European law, enforced since 2018, about data protection. According to Wikipedia: " The GDPR aims primarily to give control to individuals over their personal data and to simplify the regulatory environment for international business by unifying the regulation within the EU."
I was in a discussion about our releases through OTRS with a fellow Wikimedian, and it was mentioned to me that no where in our release process people acknowledge that they are aware that their name will be hosted on Commons and with every copy of the file everywhere, when they release an image with the CC-BY licenses. Should this be added to our Uploadwizzard, and to the declaration of consent maybe? Ciell (talk) 11:43, 22 February 2020 (UTC)
Any newbie will be using the upload wizard, which for an 'own work' defaults to CCBYSA and says:
I, <user>, the copyright holder of this work, irrevocably grant anyone the right to use this work under the Creative Commons Attribution ShareAlike 4.0 license (legal code).
(Anyone may use, share or remix this work, as long as they credit me and share any derivative work under this license.)
That's probably sufficient. As a slight tangent, courtesy deletions are a thing for newbies with new uploads, and the idea that the GDPR reaches into the USA servers is probably wrong. --Fæ (talk) 14:22, 22 February 2020 (UTC)
And the servers, nor the country where de Foundation is settled, does not define which copyright is applicable Fae? I hoped that old idea was removed from Commons years ago? It is the country of first upload and the country through which the website is accessed, so I've learned. Ciell (talk) 17:00, 22 February 2020 (UTC)
No, true. But with GDPR, if a website is accessible from Europe, it has to be complainant as well as far as I've understood this law. Ciell (talk) 18:19, 22 February 2020 (UTC)
It is worth noting that Creative Commons Attribution 4.0 licenses include a provision requiring that attribution be removed from a work if the author requests it. Previous versions of the license have a similar requirement that only affects collections and adaptations, not the original work. If we recieved a request to remove attribution from a CC-BY/CC-BY-SA 4.0 work, we would have to honor that request. --AntiCompositeNumber (talk) 14:48, 22 February 2020 (UTC)
Yes, but the European GDPR says you have to actively inform people and seek consent about what you will be doing with their personal data before they release it, so notice and take down is not enough in this case.
Hi! The publication of an author's name does of course constitute processing personal data under the GDPR. In the case of a CC-BY-licensed work, the legal basis for this processing activity is compliance with the license agreement (art. 6(1)(b) GDPR). In other cases, the legal basis is compliance with the statutory requirement to name the author (art. 6(1)(c) GDPR). As a result, we don't need any form of consent (art. 6(1)(a) GDPR). Hope that helps. (IAAL specialising in data protection with a Ph.D. in copyright law, so I'm happy to answer any other questions in that regard.) -—Gnom (talk) 11:46, 23 February 2020 (UTC)
@Gnom: musea ask "what about the heirs?" If the heirs send an email to OTRS, and release images that they inherited:
Of course we need to attribute the original author/maker, but what about the person(s) that released the rights? Do we have to list their name online (we don't do this now), because they are now the official rights holders? Ciell (talk) 19:06, 24 February 2020 (UTC)
The files are identical apart from jpeg encoding, hence they are different file sizes. Both are widely used, but you can pick the one you think is better and use {{duplicate}} on the other one. --Fæ (talk) 16:51, 24 February 2020 (UTC)
Thanks for confirming that the images are identical. Exif of another photo uploaded by Zsolt Dudás indicates that he was in the area (in Timișoara) at the time. So, did Radu Bogoevici take over the photo taken by Zsolt Dudás? :) Just ask.
Guidance on category naming (specifically, those starting with a quantity)
Joshbaumgartner started a discussion at Category talk:Groups about standardizing category names for groups of objects. Only one other person commented and the discussion was closed. Joshbaumgartner has begun renaming categories and recategorizing images based on that discussion. When I noticed that he had moved Category:Two cats to Category:2 cats, I started a discussion on his talk page. Standard English usage is to spell out quantities if they are at the beginning of a sentence or title. So a picture of 2 cats would be in category:Two cats but a package of 2 donuts would (hypothetically) be in "category:packages of 2 food items". I understand Joshbaumgartner's reasoning and I am sure he is doing this with the best intentions, but to prevent future disagreements, can we get some other opinions about this change? Thanks. World's Lamest Critic (talk) 22:41, 19 February 2020 (UTC)
Please discuss it here instead. I started this discussion here so that we could get more input and visibility. Let's get consensus on the general points first. World's Lamest Critic (talk) 23:35, 19 February 2020 (UTC)
I would agree that this is of broad enough concern that we should have the discussion on the VP.
The value in spelling out the words is that it's more consistent with standard English, where starting a sentence/title with a numeral is usually considered awkward.
The value in using numerals is that they are shorter (particularly for higher numbers), potentially easier to use with templates, enable consistent use of one format across all categories (rather than the inconsistency of Category:Two food items and Category:Packages of 2 food items)
Ich kann dem nur zustimmen, irgendwelche Feinheiten des Hochenglisch sind irrelevant, hier geht es um möglichst einfache Sachen in einem internationalen, definitiv nicht nur monolingual-anglophonen, Umfeld. Daher sind Zahlen klar zu bevorzugen.
For the monolinguals: I have to agree, some fineprint about niceties in the english language are irrelevant, here all should be as simple as possible, as it's an international, definitely not monolingual-anglophone, project. Thus numbers are the choice to be made.
Olá! Ik praat wel nog nederlands, en heb latijn en russisch op school gehad, dus ik kan het en beetje lezen. Ik heb geen flauw idee van portugees, maar het was gemeent alleen voor de monolinguals, niet voor mensen as jou ;) Grüße vom Sänger ♫ (talk)09:16, 22 February 2020 (UTC)
I'm fine with the awkwardness of starting category names with numerals, as long as there's no objection if someone wants to create category redirects that spell the numbers out. Note that I am not suggesting that we automatically create redirects for all such cases. --Auntof6 (talk) 19:26, 20 February 2020 (UTC)
Although I was the one who started this discussion, I don't have strong feelings about it and I will obviously go with the consensus here (which seems to be that starting categories with numerals is fine regardless of English language convention). There's no manual of style here like the MOS namespace on Wikipedia. Should this get written down somewhere? World's Lamest Critic (talk) 04:32, 25 February 2020 (UTC)
Can we please talk about the competing, confusing, and redundant forms of data applied to media here?
We have:
Notes that we can add to photos
File information captions and structured data
These can be added via either the upload wizard or later when Commons asks you to add tags but you cannot add any tags you want then, only ones that are suggested
Additionally, structured data has "depicts" as a default but there are many other types of data to be added here and it's not clear what they all are or how to edit them
The {{Information}} template that includes the description field
This is also edited via the Upload Wizard alongside the caption field and there is no clear reason why these are both present
An extensive and very arbitrary category system
Some of these are saved and edited in the standard method of MediaWiki, some are hidden in the cloud somewhere via a data add-on, notes are added via a button to create rectangles on a surface.
Is there anywhere where we have broken down the distinction between these and when we should use one versus the other? I have been here for years and this sudden explosion in seemingly random and overlapping forms of adding data to media files is very confusing. I also have no clue why we are storing data locally instead of at d:. —Justin (koavf)❤T☮C☺M☯09:28, 21 February 2020 (UTC)
Unfortunately this was a WMF funded "drive" to do something about data, making Commons do stuff that piggybacks on the success of Wikidata.
In the rush to do something, there was no clear understanding, consensus or even proposal that set out exactly why these were useful or realistically of value to systematically roll out across the millions of media files hosted on this project, or what this then means for the current massive investment in volunteer time and content which is and should remain entirely embodied in wikitext.
The changes to the upload wizard, in particular, are especially damaging. It not only makes no sense to force every upload to have "captions", but this is now a huge hole in our system for near untrackable vandalism and defamation, and is actually stopping users from correctly writing or improving the description field.
The "experiment" is a failure, and it would benefit the community for us to use formal proposals to remove this unwanted and unrequested rollout driven by a need to "succeed" in rolling out data stuff with almost no regard for the consequences.
Captions, annotation and categories are not redundant, they do not have the same purpose. Structured Data for Commons is functionally close to a superior implementation of categories, made possible by Wikidata. Rama (talk) 20:04, 21 February 2020 (UTC)
@Fæ: I think you're mischaracterizing the history somewhat. I recall people at commons wanting some form of structured metadata for images going on 10 years. (Obviously commons is a big place and i sm not saying that everyone wanted that). Opinions may have changed over time, and actual efforts may or may not have met expectations. However i disagree with the assertion that this was a WMF effort that came out of nowhere. There were definitely some people on commons historically who were pushing for something in this direction. At the very least there was general unhappiness with the category system and its inability to do complex queries (intersections, dfs/bfs), and a desire to experiment with different systems. Bawolff (talk) 05:56, 22 February 2020 (UTC)
IMHO what should have been done:
SDC is developed
SDC-query-GUI for everyone is developed
commons is populated with SDC for existing media on database level by batch jobs
SDC-query-GUI is made available
people are asked to test querying GUI
corrections
people are asked to add SDC to media
What happened:
SDC is developed
an arkane query-system for experts is created
people are asked to add SDC to media
bots are starting to add SDC
random users of the smartphone app add random data to random media
@C.Suthorn: I am not sure what you mean by “an arkane query-system for experts is created” − I would assume you are referring to SPARQL, but SPARQL querying is not yet really available for Commons so I’m not sure. (Also, if so, it’d be misleading to say that SPARQL was “created” since it’s a standard very much used elsewhere)
On that topic, I still stand by the comment I made a couple of weeks back:
I think the future is not in everyone learning Sparql, but in having nice front-ends which write the underlying code for you. VizQuery is one example that helps writes queries ; Crotos or OpenArt Browser help browsing artworks in a (IMO) very pleasant way. I can well imagine such tools covering 99.9% of the cases.
(and yes, for the last complicated 0.1% one might need Sparql. For what it’s worth, I have done many many Sparql workshops in the past few years, and I must say, many people quickly grasp the basics − well enough to take an example query “depicts cats in 2002” and tweak it for their needs into “depicts dogs in 2016”).
Also, many discussions (not this one) around finding things in the category tree go “just do a Category intersection/deep category traversal” − using something like Petscan is not exactly something easy either − it can be learnt of course (just like Sparql ;-) but I’m not convinced the average Commons would find that easy :-).
I agree with Bawolff here, as I recall for over a decade we were complaining about our bizarre category system requesting solutions witch would allow some sort of "tag" system so if you are interested in Category:Portrait paintings of women of Spain in national costumes than you add tags for: portrait, painting, women, Spain, national costume. Also we were asking for years about some solution to image organization which does not depend on knowledge of English language (since we are multilingual project). SDC depict statements seem to be a solution which addresses both of those long time requests. Another long complained about issue is that wikitext, which is great for writing articles is not the best way to implement language independent storage for image metadata. Many tools need to be able to look up image license, author, creation date, camera coordinates, etc. but storing them as wikitext prevent easy access to the data. SDC will allow us to easy access those and build much better tools in the future. However at the moment we are stuck at doing many things twice, the old way using wikitext and the new way using SDC. --Jarekt (talk) 15:31, 22 February 2020 (UTC)
"the old way using wikitext and the new way using SDC"
This is the first time I have seen the lobbyists for SDC admit that their mission is to get rid of wikitext.
As for the justification that SDC gives us "tagging", no, rubbish like captions are just confusing new users and damaging actual usable searchable content like description text on the image pages. To date, there is zero evidence that SDC will be in the least bit useful, instead, it's a great tool for systematic and undetected vandalism and defamation. --Fæ (talk) 15:35, 22 February 2020 (UTC)
“lobbyist” is a somewhat loaded word, which has unfortunate implications.
This seems an opportune moment to say again that my (I think) quite coherent proposal for how structured data could support rather than duplicate or replace the category system was roundly ignored, except for one person who basically derailed things enough that I walked away in frustration. - Jmabel ! talk16:37, 22 February 2020 (UTC)
I agree that the SDC project is not ideal, but it is to late to reverse the decision. A reversion would cause even more confusion and damage. Personaly I ignore SDC as much as posible and put my energie in improving the category structures. No reason to stop work there, as SDC wil never replace usefull categories. There are actualy templates wich eliminate a lot of work in creating new categories. I only check the SDC mutations on the files on my follow list.Smiley.toerist (talk) 11:03, 23 February 2020 (UTC)
Neither do I. It looks like an awful way to report this. @Jarekt: why would you want a hidden category for this, rather than running a report only you need it? --Fæ (talk) 17:41, 18 February 2020 (UTC)
Was there any consensus that files with a location template require SDC coordinates? And what is the point of SDC coordinates, is there a help page?
I may be missing something, but this looks like pointless categorization (of 3,195,703 files and at least 83,000 are my uploads) when a report can be pulled of these were anyone wishing to do something with these files. --Fæ (talk) 10:42, 19 February 2020 (UTC)
Looking at this slightly further, this category has been added to over 3 million files, but there was no community discussion. It has been added to templates in a way that means that only administrators have access, and no non-sysop editor is allowed to remove it from files. These are now built into location templates effectively warning all users that their files lack SDC coordinates, when there has been no consensus that hiding coordinate data inside obsure and non-standard SDC fields outside of wikitext is either sensible or useful for this project.
Jarekt, could you advise how to reverse this and who is responsible for the changes? The burden to achieve consensus for mass changes like this is on the people making the change. There should never be a burden imposed to reverse it. Thanks
Hi Jarekt To my latest photo I've added the property as you adviced, but the category is still there. So please adress my question: a) What to do to get rid of the category; because for readability reason I try to keep only as few categories as really necessary? b) What is the added-value for a single photo if the coords are in the SD instead of file description? c) If it's necessary, may a bot take the coords from file description (most of my photos have coords) and copy it to SD, because I cannot manage it all by hand, thank you. --A.Savin13:35, 19 February 2020 (UTC)
If you want crappy pseudo-categories nagging everyone about SDC (and frankly putting us off ever cooperating with SDC related projects) then make a formal proposal and explain exactly why Commons must suffer this crappy solution, when all you have to do instead is pull a report when, and only when, you actually are going to work with the data.
Hi Jarekt you still didn't respond a) What is the added-value for a single photo if the coords are in the SD instead of file description? b) What can I do to get rid of these categories from my uploads; it doesn't matter what is the precise name and purpose, the only thing that matters is that there is an obviously superflous category with some cryptic name, and I just wish useful categories with understandable name for my pictures. I'm waiting. Thank you. --A.Savin20:36, 21 February 2020 (UTC)
@A.Savin: The value will be being able to find the photo with a query, and combine the coords with information in other SDC fields -- eg 'find photos of flowers taken within 2km of this point', 'what are the most common types of buildings shown in photos within 5 km of this point' etc. Having the coordinates as statements in a database opens up all sorts of possibilities for discovery and retrieval that just aren't available if all there is is wikitext in a template. Jheald (talk) 23:03, 21 February 2020 (UTC)
@A.Savin: Sorry, I did not realized that the purpose of SDC is unclear. Jheald had one great example, but you should think about SDC as a database and you use it for the same purpose you would use any other database. Actually coordinates from Commons are already being held by at least one database allowing several tools that show you on the map all the nearby commons images. The SDC database is still in pre-beta mode, but you could see how it works on Wikidata. For example to see photographs of different mosquito species you can type SPARQL like this and after you run it you can display the images by picking "image Grid" option at the menu at the center left edge. The categories are not "obviously superflous", since they are being used by people working on SDC. I do not understand the need to micromanage hidden categories. Those categories are optional and can be easily turned off, so that they are not visible. There is always a trade-off between category length and how cryptic is the name. I opted for long, and what I was hoping descriptive category, but seem to have failed in the descriptive part. We can make them much shorter and more cryptic if that is preferable, for example we could change Category:Pages with local coordinates and missing SDC coordinates to Category:SDC P1259 missing and explain at the category page the details. Shorter categories would be much harder to spot. --Jarekt (talk) 05:00, 22 February 2020 (UTC)
Why not remove all location templates ? Put them in databases and create a nice interface to that, like here ? Humans manually editing coordinates is ancient and most of us can't edit them without copying the coordinates from other mapping service like google map or open map. -- Eatcha (talk) 04:11, 24 February 2020 (UTC)
Looking through recent Speedy deletions using the F10 rationale: Personal photos by non-contributors, it seems tricky to interpret the criteria "This includes low-to-medium quality selfies and other personal images of or by users who have no constructive global contributions". As the commonly used Quick Delete gadget makes it easy to just look at a recently uploaded image and tag any selfie with F10, it is likely that new contributors to other Wikipedias have a rather rude welcome to Commons. This is exacerbated by the experience of good-faith users going through the help materials available in their language or joining a local editathon, which often encourages new users to experiment with Commons by uploading one of their own photographs to put on their Wikipedia user page.
I suggest we interpret CSD F10 to enforce the no constructive global contributions criteria more literally. As in if the uploader has any constructive global contributions, that they are always permitted to have at least one profile photo if it is released in accordance with Licensing policy. It would be super if the Quick Delete tool made helpful information available like a tiny set of global contributions numbers with links to the contributions, which at least then makes it easy to see that this uploader may not have done anything else on Commons, but they happen to have some edits on another project where they might be a good faith contributor. Given that speedies happen so quickly and that our undeletion appeal process is so unfriendly, there should be a helpful approach to good faith selfies from genuine Wikipedians, rather than risking that they are slapped away from testing out Commons using a correctly released profile photo so that they don't come back.
Saying this, the vast majority of 'selfies' are out of scope, even from those with over 80 edits on another project, from contributors wanting to create their CV on a user page or to promote their website. Others marked as F10 are actually being deleted due to being copyvios (G11) or spam (G10 or U3), and those tagging these types of files should be encouraged to use more specific criteria.
Selfie candidates for speedy appear in Personal files for speedy deletion, though at the time of writing it is empty, as selfies pretty much get deleted on sight.
Any thoughts on a proposal to improve the CSD guidelines or to make the gadget more informative for maintenance CSD taggers? --Fæ (talk) 14:24, 25 February 2020 (UTC)
Support Good call. See also Commons:OTRS/Noticeboard#OTRS_&_Wikidata, where it turns out that wanted photographs of individuals with items on Wikidata (established 2012) are being rejected, unseen by the commons or Wikidata communities, by OTRS volunteers, based on a 2010 policy that is on a password-protected Wiki. (Note: this is already being discussed at two venues, including the page I link to; I don't mean to open a third). 14:40, 25 February 2020 (UTC)Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits
As the original author of that speedy deletion criterium: It was always meant to be taken literally. "No constructive global contributions" is supposed to mean exactly that. Selfies of users that have a constructive contribution can always be nominated for a regular DR. Unfortunately we have some mass taggers that are quite careless and sometimes admins will not take enough care to double-check speedy nominations: Converting a speedy DR to a regular DRs is always an option (except for files that need to be oversighted) and should be the default option taken when unsure. Sebari– aka Srittau (talk) 14:56, 25 February 2020 (UTC)
Comment This does need some work - it seems to be used ruthlessly at times and not at all at others. Personally I have no issue with one person image used or not generally. However I would prefer to see contribs (useful) that go beyond that one image. Multiple images and nothing else is simply (ab)using Commons. 80 edits elsewhere can simply be a user experimenting with their user page... --Herbytalk thyme15:04, 25 February 2020 (UTC)
To be fair, the vast majority of F10 deletions are completely understandable and this is not a dig at the general process, just that we should remain alert to improving the experience for newbies, especially those that have insufficient skill in English to work through challenging a speedy on their own profile photo.
Useful - thanks. A look at random through these simply shows me some files/pages that probably should be deleted and the odd account that probably is only here for self promotion. In many cases the en wp user page has been deleted too. Still think that something firmer in the way of guidelines/policy would be useful. --Herbytalk thyme16:07, 25 February 2020 (UTC)
I had a small problem with loading
I had a small problem with loading this image. It seems to be royalty free (CC BY-NC 4.0), but the upload did not happen as I expected. The information is below the yellow areas. Mário NET (talk) 00:10, 26 February 2020 (UTC)
I'm sorry for this. It is a lack of technical knowledge on this subject of copyright. I will remove this image from the article I'm doing. Mário NET (talk) 01:30, 26 February 2020 (UTC)
cc-by-sa-4.0. I would have thought that it is still understandable if i shorten the name of the license that is the default in the upload wizard, that is generally given as the state of the art and that the vast majority of files at commons come with? --C.Suthorn (talk) 03:51, 26 February 2020 (UTC)
I need to learn carefully the technical language of these licenses. For now, I think I should just upload images that I have made or some images that are deposited in very old books. Obviously, due to the quality of the images I uploaded, the interest was to improve the articles and not bring complications to Wikimedia Commons. In my profile it is written that this page will not be confronted about my activities on it. Mário NET (talk) 14:17, 26 February 2020 (UTC)
For now you should clean up the files you already uploaded. If there is an "NC" on the source page, you will need to file a DR for the upload on commons, and if you uploaded a file you did not create yourself, the source is not "own". Once you have cleaned up, you will have learnt about these issues and you can go on with uploading from old books or other sources, but please go through your old uploads first. --C.Suthorn (talk) 14:28, 26 February 2020 (UTC)
"For now you should clean up the files you already uploaded. If there is an" NC "on the source page, you will need to file a DR for the upload on commons, and if you uploaded a file you did not create yourself, the source is not "own". " <--- I don't understand this technical language very much. I learned to write my Wikipedia articles by being beaten by other users about what it would be like to do them. I have to learn how to clean articles and how to reset DR for NC pages. The only images of mine are the ones I record about my username. To give you an idea, I'm using Google Translate for communication. Do you know of a Wikimedia Commons scheme that teaches you how to do it? Mário NET (talk) 21:47, 26 February 2020 (UTC)
You've got it right. But the way, if at times you find it easier to express yourself here in Portuguese, there are probably a good number of us here who can read that with at least moderate facility, and a few at a native level. - Jmabel ! talk00:12, 27 February 2020 (UTC)
̆Let's say that I understand English with some ease, but not technically in technology, because most of the articles I do have sources in English, as they are about nature. I will put this in the photos. Thank you. Mário NET (talk) 00:39, 27 February 2020 (UTC)
Additional interface for edit conflicts on talk pages
Sorry, for writing this text in English. If you could help to translate it, it would be appreciated.
You might know the new interface for edit conflicts (currently a beta feature). Now, Wikimedia Germany is designing an additional interface to solve edit conflicts on talk pages. This interface is shown to you when you write on a discussion page and another person writes a discussion post in the same line and saves it before you do. With this additional editing conflict interface you can adjust the order of the comments and edit your comment. We are inviting everyone to have a look at the planned feature. Let us know what you think on our central feedback page! -- For the Technical Wishes Team: Max Klemm (WMDE)14:14, 26 February 2020 (UTC)
Automobile logos
User:Jonteemil is on a mission to delete all pictures that contain automobile logos. Are there guidelines for this? We have categories such as Mercedes-Benz stars that have existed for years with no problem. Is he overreaching or should we all stop uploading such images? Thank you, mr.choppers (talk)-en-01:00, 22 February 2020 (UTC)
Thank you for linking to those discussions. It was stated there that "2. the majority of the images depict the manufacturer's logo "in situ" i.e.: on their product , which is fair game; the legal issues would only be a consideration here if one created an image of the logo outside the context of the manufacturer's (legit) product(s), signage, etc. and/or applied the logo to unlicensed products."
I don't know if that was ever cleared up entirely, but how much of the frame can be filled with the logo before it is threatened with deletion? What if I take one step back? Two steps? This ought to be cleared up so that we don't have deletion tags placed willy-nilly every few years. mr.choppers (talk)-en-01:32, 22 February 2020 (UTC)
I think if you have a photo of an entire object, like a car, then any logos are de minimis. But if you make an image of the logo alone, it's a derived work. If a photo is of only part of a car, but obviously intended to depict mainly a logo, I think it would come into the derived work category. --ghouston (talk) 06:53, 22 February 2020 (UTC)
I don't share Ghouston's interpretation. If it's e.g. on a car, outside anywhere, it shouldn't matter, which zoom the photohtapher chooses - ist's the same thing at all. The other way round: Take a pic from the front of a merc and anyone can cut out the star - what would that be ? Greetz from the baltic sea --KarleHorn (talk) 18:25, 26 February 2020 (UTC)
@KarleHorn: But that's exactly the issue with a de minimis inclusion. It's fine if a copyrighted element is present in a de minimis manner in a broader image, but you can't cut out the copyrighted element and use it all on its own without the usual rights issues arising. If you single it out like that, it is no longer de minimis. - Jmabel ! talk00:08, 27 February 2020 (UTC)
I find it strange to have pages Commons:Copyright rules by territory for territory without specific rules. I left a message to @Aymatth2: (the creator) but we don't agree on what to do: see Commons:Freedom of panorama/Americas. In particular, I'm thinking about the part of France listed in : pages all basically saying "French copyright laws apply" (which is obvious when you know France) and it has effect on pages like Commons:Freedom of panorama/Americas where you can read No information available which is not really meaningful nor true.
Of course, I could update, improve, maintain and translate the 165 pages listed on Category:Copyright rules of France but I think it would be easier and better to just turn these pages into redirect to Commons:Copyright_rules_by_territory/France while Aymatth2 think that « It is helpful to have short pages that says the laws of France apply to Guadeloupe, Martinique etc. ».
We need more point of view to make a decision, so what do you think?
I'd say that pages explaining that the copyright laws of France apply to Guadeloupe and Martinique are as redundant as a page explaining that the copyright laws of France apply to Normandy. They're all considered regions of France and therefore part of France, not soverign entitites. A redirect back up to COM:CRT/France would make sense. If we cross the Channel to the UK, however, their overseas territories are in a bit of a different situation. Not all of the British overseas territories, which are (at least somewhat) self-governing, have adopted the 1988 Copyright Act, so it makes sense to have pages explaining the copyright law in Saint Helena, Ascension and Tristan da Cunha and Gibraltar --AntiCompositeNumber (talk) 20:11, 23 February 2020 (UTC)
Module:Countries and sub-modules like to Module:Countries/Americas are used by many pages, such as Category:Cayman Islands. The modules render lists of sovereign states and dependent territories. Each entry may be passed to a template for further formatting.
Dependent territories often have different copyright rules from their parent country, as with Aruba or Bermuda, but may have the same copyright rules as with Guadeloupe or Puerto Rico. Typically our contributors will not know whether the territory has different copyright rules or the same rules as the parent. In fact, a tourist on a Caribbean cruise may not know that Barbados is an independent country, while Martinique is simply a department of France.
If we wanted to exclude territories with the same rules as their parent from the lists like Commons:Freedom of panorama/Americas, we would have to clone the large and complex Module:Countries and sub-modules like to Module:Countries/Americas, cut out the same-rules territories, and then maintain the clones independently as countries become independent (e.g. Kosovo, South Sudan) or change their name (e.g. North Macedonia), or as semi-independent territories adopt different laws or the same laws as their parents, as is possible with New Caledonia, Greenland etc.
I see no reason to make it harder for our contributors to find out what copyright rules apply to territories that happen to follow the same laws as their parent country, while adding maintenance costs.
Perhaps I'm missing something, but is the relation of Martinique to France any different that the relation of Hawaii to the United States? - Jmabel ! talk01:32, 24 February 2020 (UTC)
Functionally, and especially for the things Commons is concerned with, no. The French overseas regions are regions of France that just happen to be outside of the contiguous borders of France. --AntiCompositeNumber (talk) 02:59, 24 February 2020 (UTC)
Most French would know that Martinique is just a French department like any other. But a Brit snapping pictures on his Caribbean vacation might be unsure of the status of the island, since British ones like the Cayman Islands have their own laws, and some that were British are British no more. How about Puerto Rico?
For some reason, lost in the mists of time, we decided that Module:Countries would include sovereign states, dependent territories and major islands or island groups. That decision would be hard to undo. If we want overviews like Commons:Freedom of panorama/Americas to exclude fully-integrated islands like Hawaii and Martinique, we would have to create a clone of Module:Countries, and would have to maintain it as places like Greenland flickered into and out of compliance with the parent country laws.
Given that many contributors will be vague about the laws that apply on the islands, it seems easiest and most consistent to just keep using Module:Countries for the copyright overviews, with small pages that say, for example, Martinique is covered by the laws of France. Aymatth2 (talk) 12:59, 24 February 2020 (UTC)
@Jmabel: yes, Martinique/France is similar to Hawaii/United States (with Hawaii being a bit more independent).
@Aymatth2: I'm a bit lost and not sure to understand, please don't change Module:Countries, we need this template to list territories like Martinique in some cases (the « the mists of time » probably being the ISO 3166-2), copyright is just not one of this cases. And if we turn the pages into redirects, I'm not sure we need to change anything to the template.
If Martinique is to remain in the Commons:Freedom of panorama/Americas overview, how is a redirect more useful than a small page that says Martinique is part of France, with the same copyright laws, see COM:CRT/France? If it is to be purged from the overview, we need to create and maintain a clone of Module:Countries that selectively excludes territories with the same copyright rules as their parents. Why bother? Aymatth2 (talk) 15:27, 24 February 2020 (UTC)
Thanks. I think you could cut translation effort by using a template for the section content like
{{see|Commons:Copyright rules by territory/France#Copyright tags}}
That way, only the headings have to be translated, which should just means accepting the suggestions, although for some reason the translation aids are not showing up when I try to translate COM:CRT Guadeloupe into French. Aymatth2 (talk) 13:37, 27 February 2020 (UTC)
@Aymatth2: yes, there is still a lot of work to do on this page before translating it (and the 164 others). I was looking into using autotranslated section title. Cdlt, VIGNERON (talk) 15:08, 27 February 2020 (UTC)
@VIGNERON: I have made some changes to COM:CRT Guadeloupe and its translations. I think this is a reasonable format that could just be copy-pasted to the other 12 territories. I can do that, and do the translations. It means that an overview like Commons:Currency/Americas gives links for the overseas territories like
The user can jump directly to what they were looking for. Getting that to work involved making a {{Comsee}} template based on page language rather than user language, which was missing, and tweaking the {{CRT shortcut}} template to render an anchor, so those are side benefits. Aymatth2 (talk) 15:39, 27 February 2020 (UTC)
For those who are in the US, the Office of Science and Technology Policy is taking public comment on making unclassified published research, digital scientific data, and code supported by the U.S. Government open to the public. Go and comment please. This aligns with our mission. GMGtalk23:20, 27 February 2020 (UTC)
Removal of a few hundred images originating from Beeld & Geluid Wiki
This Commons category contains 761 files from Beeld & Geluid Wiki of Dutch & other European amusement and television personalities, dating from ca. 1950 to ca. 2010. The category is diverse in scope and quality. Most files were uploaded to Commons in 2010. Currently 581 files from this collection are used 5423 times in Wikipedia and Wikidata. The license of these files can’t be found on the resp. webpage at Beeld & Geluid Wiki (text on that web page about the license was recently clarified). None of these files are included in the official list from Beeld & Geluid containing ca. 19.000 B&G files with a CC-BY-SA license. Beeld & Geluid Wiki stimulated broad usage of their collections in the past, and files were uploaded to Commons despite a not very clear license.
The dilemma is obvious: these 761 files are heavily used and quite unique photographs (453 photos used in Wikidata), but the status of their license is unclear. Here is my proposal to approach this matter.
(March 2020) Delete the 180 files from this category not used in Wikipedia or Wikidata.
(March 2020) Remove ca. 5 obviously problematic photographs. (E.g. removed from Beeld & Geluid Wiki, see Groenteman & Hunkar). These photographs can be quickly identified.
(March 2020) Contact Beeld & Geluid Wiki about some categories of photographs very likely to have a CC-BY-SA license (Eurovision 1958, Ja zuster, nee zuster, Stiefbeen en zoon, De glazen stad, Hadimassa).
(March – May) Warn the community that 581 heavily used files risk being deleted, and give the community a 3 month period to replace these photographs in Wikipedia by correctly licensed content.
Help transcribe UNESCO archive photograph image descriptions so they can be added to Commons
Hi all
UNESCO is preparing to share 1000s of images with Wikimedia from its archives on all kinds of amazing things. But they have a problem, the metadata isn't digitised yet, so they've made a crowd sourcing platform to help transcribe the metadata. Please help out, I think it could get finished pretty quickly if several of us did some each.
Hi everyone, there are thousands of files waiting for license reviewers, but we don't have many active reviewers . If you are not a reviewer then please consider applying at Commons:License review/Requests. It's one of the boring tasks on commons, make your mind up before applying for this right. No educational qualification required.
why is there a Category:Videos needing display resolution category?
why are files added to Category:Videos needing display resolution category manually instead of just adding the approbiate video display resolution category?
why doesn't a bot simply add all videos without a or with the wrong display resolution category to the correct display resolution category?
why doesn't this bot (that does not exist) also add the display resolution SDC to the video?
As the mediawiki software adds the display resolution to the file description page automatically on upload, why doesn't the mediawiki software not also add the display resolution SDC and category automatically on upload making all this manual and botted edits that only fill up the file history redundant?
Because it is not about one person. Es ist ein krankes System. Wofür übehaupt diese Kategorien? Warum werden die nicht automatisch oder durch eine Vorlage gesetzt? Warum wurde das nicht durch SDC ersetzt? Geraade die Auflösung eines Videos oder eines Bildes ist nun ein objektiver Wert, wird von der MW-Software selber ermittelt (immer, immer fehlerfrei), warum gibt es da überhaupt eine Edit-Möglichkeit für Kontos oder Bots? Eine sinnvolle Verwendungsmöglichkeit wäre mit deepcat gegeben, aber zum einen hat deepcat kein einfach verwendbares grafisches Interface zum anderen funktioniert deepcat auf commons auch nur manchmal. Eine Abfrage von SDC mit sparql wäre hier wirklich möglich, weil für die 60 millionen Mediendateien gerade dieser Wert unveränderbar bekannt ist, aber nein, lieber wird darauf gewartet, dass dies nach Jahren oder Jahrzehnten vielleicht mal von einem Bot eingetragen wird. Es ist ein krankes System und die meisten verschließen davor die Augen. Stattdessen soll ich jemanden ansprechen, der einfach nur Kategorien füllt, die es gibt, aber eigentlicht garnicht geben müssen dürfte. --C.Suthorn (talk) 03:17, 29 February 2020 (UTC)
Commons follows the Bridgeman case so Commons doesn't recognize any new copyrights on faithful productions of 2D art that is public domain. {{PD-Art}} can be used with paintings and notes that outside the US, re-use could be restricted. Abzeronow (talk) 17:33, 29 February 2020 (UTC)
It could be {{PD-UK-unknown}} and {{PD-1996}} since it's from Bassano Limited and 1921 + 70 + 1= 1992. This from the source "Sir Frederick William Moore by Bassano Ltd, whole-plate glass negative, 2 November 1921, Given by Bassano & Vandyk Studios, 1974" would be the only wrinkle there. I think {{PD-Scan}} works if this is indeed PD-1996. @Clindberg: Abzeronow (talk) 15:50, 1 March 2020 (UTC)
Yeah, since it's anonymous, everything depends on when it was published and/or made available to the public (for the UK copyright status) and when it was published (for the U.S. status). All we know is that it was a glass negative -- if that particular negative had never been published, but the 1974 donation counted as "making available to the public", then UK copyright will expire in 2045 (70 years from making available to the public). If it was not "made available to the public" until after 1991, then it would be public domain in the UK (it becomes PD 70 years after creation if not made available to the public in that time frame). For the U.S., if the 1974 event counted as "publication", copyright would expire in 2070. If however publication did not happen until after 2002, it would be 120 years from creation or 2042 before it becomes PD. If first published between 1978 and 2002, U.S. copyright would last until 2048, due to a special provision in the 1978 law. It can get very difficult for situations like these, where we are not sure if the photograph was actually published or not. Looking at the NPG's site, they seem to have three portraits of that person -- two from Bassano negatives, and third Bassano portrait from a print, which looks to be the one Bassano published from that photo session. For the print one, since we know it was published in 1921, it's PD-UK-unknown and both PD-1996 and PD-US-expired. The other two, the NPG may have a case for depending on publication details. For the original question, there is no one single license for NPG works -- most of them will be UK works and follow that law, but the details on each can matter. Carl Lindberg (talk) 21:46, 1 March 2020 (UTC)
Smithsonian Releases 2.8 Million Images Into Public Domain
@Fuzheado are you/WMDC[6] working on a systematic import? Or is the idea that volunteers will upload piecemeal? Trying to get a sense of what's already organized. czar11:34, 27 February 2020 (UTC)
I might start taking a look at these, I think my only prior uploads from the archives were a few via their Flickrstream. If there is an 'official' project, obviously it makes sense for me to spend time on other stuff. --Fæ (talk) 11:38, 27 February 2020 (UTC)
@Ghouston, Fæ, Czar, Sadads, and KellyDoyle: - Thanks for the interest folks. Yes, we are working with the Smithsonian on a coordinated upload strategy and have gotten into the details, so if you can hold off on any large scale uploading that would be appreciated. Of course, targeted projects like Wikidata:Wikidata:WikiProject sum of all paintings should still BEBOLD and work on things. Details coming with a coordination page as well. If you're a Wikidatan, you can see that there is already a unique identifier for Smithsonian assets we are priming - Wikidata:Property:P7851 "Identifier for a resource held by the Smithsonian Institution" -- Fuzheado (talk) 13:44, 27 February 2020 (UTC)
For heaven's sake, let's get a co-ordinated strategy this time. Most volume-focused or just uninterested users probably won't realize this, but the previous large US museum uploads have been a complete fiasco in terms of organization and categorizing, leaving tens of thousands of images stranded in huge categories. If, as is sometimes the case, the metadata uploaded is poor, they can't be found by search terms either, so there is really no way of finding them. And/or the same image is uploaded several times. The NY Metropolitan (MMA) uploads exemplify both, but there are many others. Sometimes pretty useless metadata is uploaded, but the useful fields are not. Johnbod (talk) 15:31, 2 March 2020 (UTC)
I believe that you do not have the power to do this, but just go to the list on the left side of your file, click on "nominate for deletion" and explain the reason for withdrawing the upload. Maybe someone has a better explanation than mine. Mário NET (talk) 20:06, 1 March 2020 (UTC)
We rarely delete older versions of a file. First, keep in mind: deletion does not save any space, because it is always a "soft delete" (really "hide" rather than "delete"). Getting this done requires admin time, so we do it only when there is a good reason. Usually that means a rights issue with the older version, e.g. identifying information about some individual who, under the laws of the relevant country, has a right to anonymity, or a copyright violation where the current version fixes the issue by a crop or a Gaussian blur. - Jmabel ! talk07:29, 2 March 2020 (UTC)
Misplaced invitation to "tag" images
Screenshot
Much as I am in favour of structured data in Commons, I was dismayed to see this notice displayed after I uploaded an image just now:
Help make images more findable for everyone
Commons has a new tool that will suggest tags for images you upload if you haven't already added tags. When you confirm accurate tags, you're helping make images easier for everyone to search for.
[...]
Ready to start tagging right away? Give the tool a try by tagging popular images now!
These so-called tags are intended to be added as "depicts" statements.
There is a big difference between a "tag" and what should be a value in a depicts statement. For example, I might "tag" an image of an autumnal tree with "autumn" and "gold"; but that is not what the image depicts. I might "tag" a picture of a specimen of Quercus robur with "tree", but I would use the more precise Quercus robur (Q165145) for a depicts value.
Adding "tags" in this way will pollute the supposedly structured data with generic keywords.
Furthermore, the tool for adding them has other equally serious, flaws, as I commented recently when I gave feedback on it - in my view it is not yet fit for general release.
I've seen no community discussion of whether a notice such as the above should be displayed, much less consensus for it, and equally no consensus to use the "depicts" statement to hold keywords or tags. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits15:10, 11 February 2020 (UTC)
Support I agree with Andy that we first need a way to not just ignore or skip bad tags, but expressly mark them as "inapplicable" or "rejected", and actually (before reading his comment on the topic) posted some remarks to that effect. Gestumblindi (talk) 21:11, 12 February 2020 (UTC)
Support Just an additional comment. Andy is right, too much noise and too much useless tags. The tool is a misunderstanding of depicts. Rules similar to COM:OVERCAT should be respected, existing depict statements should be displayed. The way the tool is working produces a lot of work removing useless statements. --XRaytalk06:13, 1 March 2020 (UTC)
Comment The above comment is not crafted as an RFC-type consultation, so it's not clear what support and oppose even mean in this context. To provide a slight counterpoint: even though the system as implemented now is not perfect (nothing is), let's not rule out controlled exploratory features altogether. What should be done is to refine the scope, parameters and instructions so that if machine learning is indeed being used for image classification, it is done in a logical and useful way and not just wildly guessing at visual themes in a random image. As one of the few folks who has experience implementing the addition of depiction statements at scale using ML (7,000+) via the Wikidata Game outreach:GLAM/Newsletter/February_2019/Contents/USA_report, I can say that there are constructive ways to do this that can work. My project was helped by the fact we focused on 2D reprsentational artworks and specifically, paintings. The implementors of the SDC tagging feature may do better by gathering some more context about the nature of the uploaded image before applying generic ML techniques. -- Fuzheado (talk) 03:23, 14 February 2020 (UTC)
Comment "Tag" is the wrong word here, but I'm not sure if it's just an English issue, or if this is a multilingual issue? Can native speakers have a look at the translations to see if they are better? Thanks. Mike Peel (talk) 15:00, 14 February 2020 (UTC)
Thanks for the useful feedback you provided on the computer aided tagging talk page. We are still working on the tool and fixing bugs, but many people who have opted in to depicts suggestions find it useful, so we do not plan on turning it off completely at this time.
We do hope to add the ability for users to add their own custom tags in an upcoming release. Also, there's an existing ability to blacklist certain inappropriate/inaccurate concepts that come from the Vision API. We have already added some things to that blacklist ourselves, but we're also exploring a feature that will expose the ability for community admins to edit and add to the existing blacklist.
@RIsler (WMF): "many people who have opted in ... find it useful" That's not the issue; the issue is the quality of the data the tools is leading them to generate; and the nuisance that the tools nagging is causing to others. and the point that "There is a big difference between a 'tag' and what should be a value in a depicts statement", none of which, I note, do you address. I didn't suggest "turning [the tool] off completely", I want to know how to turn off the nagging notice described in my post above. The decision as to whether the notice - or indeed the whole tool - is enabled is surely the community's to make? Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits22:18, 14 February 2020 (UTC)
If you simply want to "turn off the nagging notice," you can click the X that you see in the top right corner of your screenshot and the notice should disappear forever. Have you tried that? If it does not disappear, then that's a bug. Keegan (WMF) (talk) 22:37, 14 February 2020 (UTC)
@RIsler (WMF): It is indeed buggy, as it reappears after every upload, even after that "X" has been clicked, which I did on first seeing it, and several times since. But I want to know how to turn it off for everyone, and especially the inexperienced contributors, for whom it is particularly misleading. I note that you still do not address my substantive points, which I repeated for clarity in my last post. To be even more clear: the tool (whose aims I very much support in principle) is no better than an "alpha" release, and should not be exposed to users, other than those familiar with both the community's intended use of depicts statements and the need to robustly test its fitness for deployment. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits23:01, 14 February 2020 (UTC)
I've created a bug report and we'll take up the specific issue of the X (ticket here). As for your other points, we agree that the tool can be improved, and the dev team have specific tasks that are underway to achieve just that. RIsler (WMF) (talk) 23:24, 14 February 2020 (UTC)
So you're not going to address them, and you're not going to say how we can have this benighted invitation notice removed for all users. The team have - on the available evidence - no specific task underway to achieve anything to do with the big difference between a 'tag' and what should be a value in a depicts statement, and no specific task underway to demonstrate consensus to use the "depicts" statement to hold keywords or tags. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits23:56, 14 February 2020 (UTC)
The issue is not how to improve it. The elephant in the room is that it completely destroys the structured approach to finding images that has developed, albeit somewhat haphazardly over the years. Search for a keyword, and if an image has that tag, it will show up in thousands of result. That's unhelpful to the point of being useless, if not actually hostile. Do it the way we do now and you are much more likely to get cogent results. It's not helped by people misunderstanding how categories should work structurally, i.e don't categorise things by their parts, which invokes COM:OVERCAT. TBH, I'm getting somewhat fed up of other projects coming here and saying "We do this, so will you", without any understandng or even consultation. No project is master. If WMF really wanted to be useful it should spend some time considering whether my block on en:WP withstands serious scrutiny, considering its inconsistency and breach of its own policy. As a former lawyer myself, I'm used to hearing lawyers laugh. Good evening. RHE out. Rodhullandemu (talk) 00:01, 15 February 2020 (UTC)
Comment The conflation of 'tagging' with the notion of 'depects', in the tool UI and in RIsler (WMF)'s response, above; and RIsler (WMF)'s unwillingness to discuss the difference between the two despite several clear invitations to do so, both are deeply worrying and indicative of a don't care / fait accompli attitude. The absence of a common frame of reference for commons depicts structured data is clearly a red flag. This has the feeling of a product-push initiative in which a tool designed to 'solve' a poorly analysed problem situation now has sufficient momentum to ensure it'll be its own train wreck, albeit one with great metrics. Wiser heads would take the hint and return to the first principle of deciding how depicts structured data should work on commons, in terms of scope, granularity and ontology, before offering an ACME tool. --Tagishsimon (talk) 02:28, 15 February 2020 (UTC)
Suggestions case-study #1 depicts: people -- photograph -- child -- standing -- snapshot -- black-and-white -- monochrome -- monochrome -- photography ?Suggestions case-study #2 depicts: natural landscape -- nature -- bank -- water -- properties of water -- tree -- river -- natural environment -- leaf -- wilderness -- sky ?
Support. Yes. Hit the brakes. *Now*. It's time to pause so the community can assess and review and analyse what has been produced in this initial trial phase, and also come to views as to how we want "depicts" to be used. It's time now to take stock and assess, *not* to ramp it up and push on blindly.
Don't get me wrong. I think the experiment is very interesting, and I do think the output is producing is interesting, and has the potential to have real value.
But just click on Special:SuggestedTags#popular and look at the kind of tags that are being suggested. For example, the tags for (on the right) the first two images I was offered:
natural landscape -- nature -- bank -- water -- properties of water -- tree -- river -- natural environment -- leaf -- wilderness -- sky
These are, I think, very very interesting. But they are very very different from the way depicts (P180) has been used so far. Given how plainly revealed that now is, it is appropriate to stop, review, discuss, and determine what it is we actually want.
Until now, inheriting practice from Wikidata, the aim for depicts (P180) has been to be very specific, very accurate, very concrete, very low noise. To identify as precisely as we can exactly what is in the picture.
The tags are not like that. They are far more general, far more impressionistic, quite likely to reflect mood or technique or atmosphere or style rather than specific concrete content elements.
Personally as I have said, I think that is quite interesting, and does have potential value. But I think Andy hits the nail on the head that this is something very different from the curated approach depicts (P180) has so far represented; and if it continues further to any degree it seems likely to rapidly destroy very much of the work that's been done so far trying to add careful depicts (P180) statements to allow precise and specific retrieval, by swamping the property in a vast amount of genericity and noise.
Another part of the problem is we are flying blind. Without a functioning SPARQL query system, we simply don't know what the tool has been doing. We don't know how many tags have been added specifically by this tool in total; we don't know which individual tags have been added and how often; we don't know in aggregate what sort of tags have been added and how often; we can't compare what the tool has done with what existing categories there may be on images; and we can't compare what tags have been added via the tool to what depicts statements there might already have been on the image by other routes.
We desperately need to be able to generate this kind of overview information, if we're to make sensible assessments. And we need to be able to robustly identify which tags have been added via this tool route -- they ought at the very least to have a wikibase reference to say this is where they have come from, so that when we do have a SPARQL system, we can identify them.
It also worries me that the community seems to have no 'emergency stop' button. If a bot runs out of control, the admin corps can block it. But if the tool is causing damage, there seems to be no way the community can stop it. That is something I think that does need to be addressed. The community must have a 'stop' button.
Ultimately, I think Andy has exactly identified the issue, that these tags are qualitatively different from depicts statements, and it is damaging to the what people expect from depicts statements, if they go on being added pell-mell.
I think the community needs to have a serious think about this -- and we need the data, to inform that thinking. But until we can do that, the immediate step *now* should be to stop adding any more depicts (P180) statements.
One possible way forward, that could be rapidly implemented, might be to create a new, different property that the tool could add -- perhaps "tag", or "keyword", or whatever. What it's called doesn't really matter, but doing so would allow the tool to continue to be being used, and to be generating data, without contaminating the specific established meaning and expectations of depicts (P180). Jheald (talk) 23:51, 15 February 2020 (UTC)
Comment I miss a proposal here. Commons is based on consensus. The consensus can be built in two ways. One is that you change something and no one protest, the other is a proposal for change and then voting. What I can see above is just a report what had happened, but the proposal is unclear. --Juandev (talk) 07:00, 5 March 2020 (UTC)
Why this matters
Anyone wondering why there is concern can see the kind of "tags" being added in this search.
File:Dubois Street in Szczecin, 2017.jpg - depicts "public road", "infrastructure", "architecture", "neighborhood", "highway", "sky", "street" (why road, street and highway?)
File:Larus argentatus in Sopot, 2016.jpg - depicts "bird", "Charadriiformes" and "Laridae" (contrast with the fact that this is also correctly and more precisely stated as depicting "European herring gull")
File:Vario LF in Samarkand 2018.jpg - depicts "public transport", "mode of transport", "vehicle", "tram", "motor vehicle" and "transport" (it actually depicts a Vario LF electric tram, Q2065153)
This is not structured data; it is unstructured noise. I don't have the resource to revert the number of bad statements I found - and all this was in one set of 250 edits.
I did, though, revert the tram example. Troublingly, although I reverted six "computer aided tagging" actions only one shows up in the page history as being "computer aided tagging reverted", so the stats will show a 5:1 ratio of good:bad edits, and cannot be trusted. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits00:52, 15 February 2020 (UTC)
Looks perfectly good to me, exactly as keywords should work. Replacing "tram" with "Vario LF electric tram" would just make it as useless as existing Category system is. --- [Tycho]talk01:26, 15 February 2020 (UTC)
How is Category:Trams useless? Catscan isn't working for me, so I don't know how many files are in the category, but it's clear there's at least a thousand. How is returning a thousand results for keyword:tram going to help anyone?--Prosfilaes (talk) 09:04, 15 February 2020 (UTC)
You are absolutely right that this is "exactly as keywords should work". But the structured data property into which these loosely-applied keywords are being shoehorned is not "keyword" or "tag"; it is depicts (P180), which has an entirely different purpose. Where was it decided, by community consensus, that we wanted to apply a plethora of redundant keywords to images, and where is the consensus to abuse P180 to do so? Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits11:05, 15 February 2020 (UTC)
If all 10k tram pictures get "depicts tram" then automatically the Wikidata tram item gets 10k "depicted by" statements, right? That will soon create technical problems and, thus, should be prevented on technical grounds alone, before even discussing how not to edit a knowledge base. --SCIdude (talk) 16:17, 15 February 2020 (UTC)
Brilliant, and for one dark hour in 2019, when I felt forced to log in for the so far first + last time since May 2016, how about limiting it to anything better than "patrol", e.g., "file mover" or "licence reviewer"? –84.46.52.15107:24, 20 February 2020 (UTC)
Understanding of "depicts" in different languages and cultures
When checking the added depicts statement of my photos I had to revert many statements they does not make sense in any way because the statement is a think that can not be a "depict" of something because is is a theoretical or philosophical concept and not a real sea able thing.
Because of that is so much I am thinking about that this is not only a problem of people do not reading the information pages. This problem could also be about the different understandings of this term in various languages and cultures.
The German translation is "Motiv" that in context of images is only about what you can see on the image, but in other contexts is also can be used more in a meaning of background or topic. Because of this I think with languages and cultures they are not so common in Europe and North America the problem could be more worse. I hope we can discuss this problem here and people can describe what theirs understanding of the term in theirs language is.
One example: At File:Rurtalsperre Obersee Urft in September 2019 32.jpg there was added nature (Q7860). My understanding of nature (Q7860) is the same as the definition in the enwiki: "Nature, in the broadest sense, is the natural, physical, or material world or universe. "Nature" can refer to the phenomena of the physical world, and also to life in general." With this definition for me it is obvious that this can not be the depict of an image. (Or is the depict of every image.) --GPSLeo (talk) 08:58, 24 February 2020 (UTC)
I know, but tool pages says: "Review suggested tags of depicted objects in images." Because of this clear task description and the link to the full information page. I was thinking about that this not only about people do not reading the manual. --GPSLeo (talk) 15:00, 24 February 2020 (UTC)
+1 with Andy. Plus, you're question itself feels too philosophical to me. The answer is language-independant and more simple: « Be as specific as you can. » as explained in the official page Commons:Depicts. nature (Q7860) was indeed wrong but because only it's too wide. I'm guessing @Amuzujoe: just followed blindly the suggestions of Special:SuggestedTags (again see previous discussion mentioned by Andy). Cheers, VIGNERON (talk) 14:56, 24 February 2020 (UTC)
I think this is about the fact on Wikidata there is no strict model for use of properties and values and this model of not having a model is broad to Commons. So then one person uses this tag, another person another tag. If you are talking about the different understandings in the different languages, the item description would help to see under tags. Moreover, there is an issue with the not proper translation of tags, which we cannot fix here now. --Juandev (talk) 07:05, 5 March 2020 (UTC)
Depicts
I was originally pretty neutral on the idea of "depicts" but I am increasingly turning against it. User:Jwale2 has been adding "depicts" content prolifically, so I hope/presume that he understands it better than I do, and I see that this change is all "computer-aided tagging" so I presume this is in line with the recommendations of a bot, but I find this edit almost indistinguishable from vandalism.
Just keep on saying it. It's rubbish, pants, a backdoor for vandalism. It should be removed from the upload wizard and any mobile app as the error rate makes it worse than useless. --Fæ (talk) 17:25, 27 February 2020 (UTC)
This has nothing to do with the Upload Wizard. I don't use the Upload Wizard; this is a photo I took; these additions described as "computer-aided tagging" are almost certainly unrelated to the Upload Wizard. I, for one, have no idea what tool was involved, since "computer-aided tagging" is far too vague to let me know that. - Jmabel ! talk04:21, 28 February 2020 (UTC)
I have been quite unsure what to do with this feature, and have not been particularly thrilled at being prompted to spend my limited unpaid human time adding data that seemed to have no use beyond providing machine-readable data for use in training computer vision models. (I'll admit to a certain glee at the thought of these models being trained on "computer-aided tagging" results as above, which has the potential of taking the GIGO principle to new heights.) In theory, there's a pretty strong case for having "depicts" data in some fashion, perhaps derived in a semi-automated way from categories and descriptions. But the current duplicative setup doesn't seem like it's providing a net benefit to the project, and as others have noted, creates abundant opportunities for both intentional and unintentional mischief. -- Visviva (talk) 18:20, 27 February 2020 (UTC)
I see that User:Schlurcher has reverted two of the most egregious "depicts" from this photo: "window film" and "psychedelic art". I am going to take it upon myself to remove the way-too-vague "architecture" and the certainly false "cathedral". But is there something we as a community can do either to get this tool turned off or to make sure that the people behind the tool make a serious commitment to review the tags that are being added, instead of making the rest of us take a bunch of time to clean up a mess they are creating? - Jmabel ! talk04:27, 28 February 2020 (UTC)
In fact, I've gone a step further: I've removed all of the prior depicts values and replaced them with stained glass window (Q21061279). This is more appropriate than any of the depicts values that were there before. In short, there was a much more appropriate Wikidata item that could have been used, but apparently either this tool didn't suggest that one or User:Jwale2 chose to reject the most appropriate suggestion. - Jmabel ! talk04:33, 28 February 2020 (UTC)
I think this was the right course of action.
I won’t presume of the overall quality of the tool’s output (as we don’t have ways like SPARQL to measure it − but the evidence we do have leans towards "not high") but I think it is increasingly clear that this tool is a net-negative when it comes to the good will of Commons contributors towards SDoC. Jean-Fred (talk) 08:46, 28 February 2020 (UTC)
Hello everyone, @Jmabel and Jean-Frédéric: . I'll attempt to clarify some things here and talk about what we're trying to achieve with this tool, the impact we're seeing, upcoming work we're doing, and how you can help.
Firstly, thanks to everyone who has chimed in so far. We recognize that some of you have concerns that the CAT tool is either not adding value or is in some way corrupting data.
One main goal is to encourage more people to add structured data to improve search and re-use. We’re particularly interested in actual users and not just bots. We are certainly seeing an increase in that regard. More users are adding data and making images more findable and searchable.
In terms of findability, we can use "architecture" as an example. We believe users searching for "architecture" is a valid and potentially common search use case. That case is not served well with today's methodologies on Commons. A plain text search returns a mix of results and includes things referring to computer architecture. The Architecture category omits many applicable files and has multiple subcategories that are difficult to browse. But a "files depicting.." search (using the feature we recently added to the search dropdown) returns a much tighter and relevant body of search results, and almost all of those were files tagged recently with CAT. This is true of a wide variety of concepts. While we understand the desire for very specific tagging only, that does not help our files become more findable.
Additionally, although the focus has been on the debate about generic tags that may or may not be applicable, there are many instances where the machine vision is pretty spot on. We now have dozens of images now findable via aerial photography, for instance. Much of what gets uploaded to Commons is generic outdoor imagery, and usage so far indicates CAT users are doing a reasonable job of describing those images.
With all that said, it's absolutely true that some users are confirming tags that aren't appropriate. We'd agree that things like "psychedelic art" for a stained glass window is just plain incorrect and we appreciate community efforts thus far to correct not only the information but also show users how to do better. With that said, reverts of CAT data, at the moment, are small in number, perhaps an average of 6 or 7 a day, and some of those reverts themselves are questionable (like removing a “canal” depicts statement when the photograph clearly has a canal in it).
Like all new things, there's often a period of transition and "figuring out" where things fit. We're in that phase now, and certainly experiencing some growing pains. But we are also seeing evidence that our file metadata is growing richer, and useful files that were buried are now findable and adding value to Commons as a place where people can find just the right image they need. There’s absolutely more to do, and we’re working on making improvements as fast as we can. If you have ideas on how we can improve things further, input is quite welcome on the project talk page. Thanks for your patience and diligence. RIsler (WMF) (talk) 00:33, 29 February 2020 (UTC)
Given what I've seen, I'm not at all sure that the small number of reverts is good news. Is anyone attempting systematic QC on the results of this, or are you just hoping that enough files are being watched that it will all work out? - Jmabel ! talk06:59, 29 February 2020 (UTC)
Hello. We're monitoring the addition of all structured data content as bots, community-developed tools, and our own tools come online. We appreciate community efforts to do so as well. RIsler (WMF) (talk) 18:29, 29 February 2020 (UTC)
@RIsler (WMF): Agreed that new things take time to suss out but there are many long-term users here have serious and fundamental concerns about how this works. There really needs to be a centralized discussion on this and some clear path forward rather than the process we have now which seems very chaotic and confusing. I think this is only going to create more problems and community backlash. —Justin (koavf)❤T☮C☺M☯18:20, 29 February 2020 (UTC)
As can be seen above, I have asked RIsler (WMF) to show where there is community consensuses for this tool to be used in the manner that it is being used. That's not an unreasonable request, yet they have not done so.
I have asked RIsler (WMF) to address the fundamental issue that "There is a big difference between a 'tag' and what should be a value in a depicts statement". He has consistently failed to discuss this point.
I have demonstrated with evidence how the statistics will show a grossly biased ratio of good:bad edits, and cannot be trusted. I have also pointed out that "I don't have the resource to revert the number of bad statements I found - and all this was in one set of 250 edits" and yet RIsler (WMF) asks us to accept that the number of reverts recorded being small is evidence of quality.
"removing a “canal” depicts statement when the photograph clearly has a canal in it" is not incorrect, if the image depicts a known canal, which has is own Wikidata item.
I think we should use this tool as a good demonstration(this word is the best example for the failed AI) that image recognition does not work well. --GPSLeo (talk) 09:53, 29 February 2020 (UTC)
@RIsler (WMF): At the moment your tool encourages clear violation of our guidelines at Commons:Depicts. See for example the version history of File:Oberbaumbrücke November 2013 01.jpg, which added lots of terrible generic statements, when one specific statement would have sufficed. Also, your about findability is flawed. A search for "architecture" should be able to find all examples of architecture using a transitive search, without needing explicit "depicts architecture" statements. If that is not supported by the search, the search function is broken. We have had 15 years of experience here on Commons with how images should be categorized, what works and what doesn't, please respect that. While I am personally excited about the possibilities of structured data and how it can help with many of the problems we had in the past, just dumping loads of depicts statements into images is not the way forward. Sebari– aka Srittau (talk) 14:01, 29 February 2020 (UTC)
Srittau's very appropriate removal of the awful tags carries no notice in its edit summary that is counted as part of this activity, so will apparently not be recorded in the supposed "number of reverts recorded being small". Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits16:04, 29 February 2020 (UTC)
Hello. To your point on tags vs depicts statements, I apologize for the delay in response. Depicts statements, historically speaking on Wikidata, have long been used to refer to more general/abstract concepts. You need only look at a sampling of the over 72,000 paintings on Wikidata with depicts statements to notice this (ex: The Three Graces) or any number of songs (ex: Göttingen). To your point about canals - I'd agree that having a more specific Wikidata item tagged is preferred, but not all canals have such names/entities and in the absence of such information a more general bit of information is quite useful. RIsler (WMF) (talk) 17:54, 29 February 2020 (UTC)
I'm very familiar with the use of depicts statements on Wikidata. All those on Q2360329 - which are not necessarily optimal - are things depicted in the painting. None of them are "history", "ancient history", "nature", "monochrome", "infrastructure", or - god forbid - "architecture", or colours, or other such nonsense, as reported here and on the tool's talk page. None of them are parent categories of the things depicted, and they don't include the taxon hierarchies of the living things depicted. But now you're ready to discuss the issues we're raising, what about the unreliable statistics? Where is the community consensus for the deployment of this tool, and this model of working? Why have you ignored requests to turn off the tool until it has been reviewed by the community, and the community has agreed by consensus to its return? Why are you ignoring what Commons:Depicts says about precision, and comments here drawing your attention to it? Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits18:40, 29 February 2020 (UTC)
Hello again. To be clear, we're not ignoring anything, and I apologize if it seemed that way. We've been as responsive as we can be, starting on the Structured Data talk page where discussions started about some bugs and feature requests, and now addressing concerns brought up here. Everything is being monitored and considered. We have been very slowly rolling this feature out over a few months, since its initial soft-launch in December, for the very purpose of measuring use, gauging feedback, and adjusting. It would seem that more recent usage needs to be looked at and we're doing exactly that. We're also trying to address each concern directly and clearly. Apologies for not getting to them all yet, but we will cover the major discussion points soon. RIsler (WMF) (talk) 19:02, 29 February 2020 (UTC)
You have been called out for ignoring questions, by a number of people. You have only just - on 29 February - replied to some of the points I raised on this page on 11 February - nearly three weeks ago - even though I and others complained about your lack of response on 14 February. You have yet to respond to requests to show where there is consensus for the tool to operate, or to use depicts statements in the manner it is - including in the very post you reply to here. Most significantly, you have yet to answer requests to explain how the tool, or the invitation to tag, can be turned off. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits19:19, 29 February 2020 (UTC)
Do we need new user rights to edit metadata? Or to have all metadata be flagged and go thru a process of review before being live? The fact that there are some machine learning auto-suggested tags makes me confused as an editor and concerned as someone using the site. —Justin (koavf)❤T☮C☺M☯14:24, 29 February 2020 (UTC)
Thanks for the suggestions. Currently, the tool in question requires users to be logged in and be autoconfirmed. No tags are added to files without a user confirming them. We're certainly open to adding an additional user right for this. RIsler (WMF) (talk) 18:36, 29 February 2020 (UTC)
The more one looks, the more bizarre it gets. File:Philae Temple R01.jpg, apparently, depicts "ancient history". And "history".
Thank you for bringing up the taxon hierarchy. An unfortunate circumstance of our current data modeling situation for organisms on Wikidata makes automated matching between taxons, related taxons, and also commonly understood names/concepts rather difficult, and oftentimes it makes solely specific depicts statements less useful than the addition of some ancillary information. We certainly don't recommend adding every level of the hierarchy, but some level of additional information in the statement is indeed very useful. I appreciate that you've taken the initiative to correct what you see as an erroneous edit. We definitely want to minimize the effort required to identify and make those kinds of tweaks to structured data, and also minimize the need for them. We're looking into how we do that more effectively as we evolve the tool. We also want to mention that some users certainly may be heavy-handed in adding taxons, while many won't confirm any at all, or just one. We're absolutely in agreement with you that some of these things need tweaks. We're also trying to balance that with uses of the tool that are in the right direction. If I recall correctly, you've advocated for some changes in taxon/common name work on Wikidata before. We're very open to your thoughts on how we may be able to account for issues there. As for the photo depicting Chinese New Year, etc. It appears the original uploader is Taiwanese, and is also the person who added the depicts statements. From their perspective, knowing the original context of the image, this data could be absolutely correct to them. It may indeed depict a ritual during Chinese New Year (although 'occurrence' is a bit weird, and perhaps something got lost in the label translation). RIsler (WMF) (talk) 18:23, 29 February 2020 (UTC)
I first raised the issue of taxon hierarchies in my post of '00:52, 15 February 2020'.
"our current data modeling situation for organisms on Wikidata... ancillary information" If we have an item for a specific taxon, what "ancillary information" would need adding? Why?
"We certainly don't recommend adding every level of the hierarchy" - you may not but your new tool recommends multiple redundant levels. This is contrary to COM:DEPICTS.
"looking into how we do that more effectively as we evolve the tool"; this is why the tool should still be in testing, not being advertised to all autopatrolled uploaders
"users certainly may be heavy-handed" - it is your tool that bears the fault here, not users, who are being presented with such recommendations by it, misleadingly described as "tags".
"We're absolutely in agreement with you that some of these things need tweaks" Don't misquote me: it is not "tweaks" that are needed, but significant and deep changes.
"you've advocated for some changes in taxon/common name work on Wikidata before. We're very open to your thoughts on how we may be able to account for issues there" That is orthogonal to the matter at hand. The issues at Wikidata do not in any way mitigate the problems described here; resolving them there will not resolve the issues with this "tagging" tool and its use.
"From their perspective..." Until someone from Taiwanese a background tells me otherwise, I don't accept that "tradition", "ritual" "Chinese New Year", or "occurrence" are what that photograph depicts, nor how the depicts property is intended to be used.
We could rename SDC to USDC (unstructured data on commons) and all would be good. The problem with the Sugester is, that you cannot not replace a sugguestion with a better tag only take it or turn it down. The other problem: If you select 23 suggested tags they are not added with on edit but with 23 edits. --C.Suthorn (talk) 19:01, 29 February 2020 (UTC)
Helo. Thanks for the feedback. We'll soon be adding the ability to add custom tags. The multiple edits issue is regrettably a technical limitation. We're exploring ways to get around it. RIsler (WMF) (talk) 19:07, 29 February 2020 (UTC)
Thanks for the question, Frank Schulenburg. There is no training data sent back to Google. Although WMF may communicate directly with Google's machine vision team about adjusting their algorithms to better suit content on on Wikimedia projects, this feature doesn't send any data back to Google and we have a layer of middleware that insulates users from any interaction with the Google Machine Vision API. You can learn more on the project page for this feature. We will be providing publicly available basic data dumps on the response data from Google's API (basically a log of which images got which suggestions), but those dumps do not include any user activity. See more information on data dump contents here: https://phabricator.wikimedia.org/T236431RIsler (WMF) (talk) 01:53, 1 March 2020 (UTC)
Thank you very much RIsler (WMF). I appreciate your answer and I also appreciate you responding on a day off. I know how difficult it is to keep an eye on discussions over the weekend (i.e. on your days off), when you're a Wikimedia employee. This is the kind of WMF interaction with the community that I, as a volunteer, would like to see more of. Because we all care about Wikimedia projects. Best, --Frank Schulenburg (talk) 03:03, 1 March 2020 (UTC)
@RIsler (WMF): I have to object to the view that "much of what gets uploaded to Commons is generic outdoor imagery" in your 29 February statement. Is "generic outdoor imagery" even a thing? Every picture, if properly identified, depicts a very specific object and/or area. It is the tool that's "generifying" everything, taking actually a "flat" tagging instead of a structured "from generic to specific" approach. Take one of my recent uploads for example, File:Luessel at Erschwil February 2020 b.jpg. It's the small river Lüssel in the municipality of Erschwil, canton of Solothurn, Switzerland. To the right is the Passwang road. There are branches of a hazel bush with catkins prominently hanging over the river. All the hills in the background have names and could be identified by a human. The image was taken this February in a location specified by coordinates on the description page. The tool, on the other hand, reduces the contents of this image to suggestions such as "tree", "water", "river", and, most generic of all, "nature". All this is not wrong, of course, as I already stated in a different thread. It seems that the tool is actually quite good at suggesting generic statements that are true. But here, they would be all thrown together with more specific statements (if the latter are added manually). I tested the tool, I actually accepted these generic "tags" for several pictures, but I have stopped, as I'm not convinced that this is really what we should do. The way it is set up, you will automatically generate huge numbers of people doing that and accepting such tags - it's like a game, it's easy, it boosts edit numbers. But I'm really not sure that it's the right approach. Gestumblindi (talk) 20:37, 1 March 2020 (UTC)
Hello, Gestumblindi. Thanks for the question. If you look at files like File:Hayman_Fire_(4).jpg, you'll see a sampling of what I was talking about. The slope/hill there might have a specific name, but most likely it does not. The trees may have a specific species, but hard to identify. The image is certainly from a specific location, and I agree that it should be listed, but we have the Location (P276) property for that. We'll soon be adding the ability for users to add their own depicts statements within the Suggested Tags interface, so that will hopefully facilitate addition of specific depicts statements, but that requires the person uploading to know that information (which won't always be the case). One of the benefits of starting with the general data is that it helps expose the image for discovery (either through search, future "related images" features, or other tools) so another user with better understanding of the material can add/edit for specificity. RIsler (WMF) (talk) 19:45, 2 March 2020 (UTC)
Thanks for the answer, RIsler (WMF)! However... I wonder what the tool would actually suggest for your example File:Hayman Fire (4).jpg. The tool offers "popular" images and personal uploads for review, but I currently can't add a specific file, I think? What this image shows, even if the hill shouldn't have a specific name, is of course also something quite specific and special: the aftermath of a forest fire, per description the Hayman Fire "burned down to soil". So, the white stuff on the ground in the image is wood ash, but I wouldn't wonder if the tool suggested "snow". And most likely not much more than generic terms like "forest", "trees" or "nature", I suppose, which would all be besides what this image is really about. I can't really imagine people wading through images of "forests" and "nature" to find an image of a specific forest fire. Which they don't have to in this case, of course, as the picture is already easy to find through "old-fashioned" means - the description, a meaningful file name, and Category:Hayman Fire. It is also an example of an image where no user, even if knowing the Hayman Fire, would have a chance to narrow the image down to that fire just based on such general data, if the uploader didn't provide the context anyway. So I still somehow struggle to see the value added by generously sprinkling very generic tags over such files. Gestumblindi (talk) 21:19, 2 March 2020 (UTC)
You're correct - there's certainly a way for people to find the image via a very specific term/concept they have in mind. What we're addressing is the gap where people don't know exactly what they are looking for - enabling discovery of interesting new relevant things in addition to returning exact matches for specific searches. We'll continuously make improvements to the tool to try to serve both cases. To your question of what the Vision API would respond with for this particular image, based on a manual test the top 5 results are Tree, Natural Environment, Forest, Northern Hardwood Forest, Woodland RIsler (WMF) (talk) 19:40, 3 March 2020 (UTC)
Well, fair enough. Though the original approach of the tool seems to offer a rather minor benefit, as I think that most of the time, people are looking for something a bit more specific ("I want to look at a lot of images of forests to discover things" sounds more like an activity for leisure time some might find pleasant), if the tool is improved to become also useful for adding more specific statements, I might even start using it again :-) Gestumblindi (talk) 21:43, 3 March 2020 (UTC)
Bots and SDCs
I have noticed, that bots and users make edits to SDC of media files on commons. There are 59.4M media files on commons and 47.9M of them do not have any SDC. Therefore is does not make any sense to add SDC to individual media files with bot or user edits. There will be still dozens of millions of media files without SDC making the whole concept useless.
I propose to stop all user and bot edits of SDC on commons until the developers have populated at least 59.3M media files with SDC. Only then users and bots can start again adding and correcting SDC that are still missing or need to be corrected.
Support Absolutely, we do not need daft "SDC needed" categories or useless SDC entries that simply copy the existing date or location on million of files. --Fæ (talk) 06:39, 25 February 2020 (UTC)
Oppose What do you mean by "…until the developers have populated at least…"? Do you expect them to do it manually? Bots should run, interface for humans should not be available for general public (what is kinda strange because humans should be more "intelligent" than bots, but clearly they are not). Anyway, I agree with your opinion expressed here. --jdxRe:09:55, 25 February 2020 (UTC)
surely not manually, that is basically what bots do at the moment. Expressed in pseude-sql (really not sql and clearly not the mw-database-scheme, but hopefully human readable):
update commons-database add inception=date1, location=location1, user=batch-update, flags="batchjob,notauser,notabot,canoverruleallprotection", sdc-a=value-a-1, .... from commons-database where date1=datevalue1 and locacation like %location$ and location1=substring(location) and ... foreach row in commons-database;
Such a batch job can do in a single night the same amount of files as bots in month or users in centuries. Each individual edit by a bot or user causes a number of sql-queries and sql-updates all encapsulated in a transaction.
An even better way might be to use the sql-dump-functinality and dump a prepared generated backup file to commons (with the wiki in read-only state) --C.Suthorn (talk) 15:12, 25 February 2020 (UTC)
Oppose I agree with Jdx, the proposal does not make sense: there is no magic way in which SDC-backed data will materialize on millions of files. Bots are a good way to go. Jean-Fred (talk) 10:28, 25 February 2020 (UTC)
Oppose I think that as long as they do not damage the information already provided these bots can copy the data. However, I would like to see the policy, that SDC is not to be relied upon at this moment. I have seen cases where upload date was copied into date created, etc. ℺ Gone Postal (〠✉ • ✍⏿) 10:37, 25 February 2020 (UTC)
Comment I Support this but only for metadata(especially EXIF). Correct statements about the content of the file are good and I see nothing against adding such statements. But for the metadata we need a server and software side solution to do not create a billion bot edits just for copying information from one database into an other database. --GPSLeo (talk) 12:35, 25 February 2020 (UTC)
Comment during SDC's design and development, the Commons community regularly, explicitly stated that structured data was to be populated by users and bots, and the Wikimedia Foundation developers were not welcome to massively batch-generate statements as is being proposed here. It's worth additional note that even if such a batch job were done server-side, it would not be able to do such a job overnight as claimed - that would likely bring the entire Wikimedia infrastructure crashing down. It would still take weeks to months to populate all of SDC, as long as it would take a bot, to avoid impacting performance across Commons and all the wikis. Keegan (WMF) (talk) 20:46, 25 February 2020 (UTC)
I have not participated in discussions concerning the actions of the SDC population. However, I suspect that the participants assumed that the SDC population is about making intellectual decisions (does a picture show a black horse at sunset?), when in fact it is about bluntly extracting SDC statements from EXIF and other metadata unchecked (and without a human looking at the data). It was hardly assumed that 5 edits would be made for a file to enter inception, location, copyright status, copyright license, and source. There are also other metadata like megapixel, resolution, camera model. In addition, there are multiple edits for depicts and 300 edits for the single insertion of captions in all languages. This results in up to 400 edits per file with 60 million files: 2 to 3 billion edits from users and especially bots. I doubt the participants in discussions expected this. --C.Suthorn (talk) 02:41, 26 February 2020 (UTC)
I took part in these early discussions, and I beg to differ − I think this was clear to these participants.
Also, I don’t believe bots are currently extracting data from EXIF.
5 edits would be made for a file to enter inception, location, copyright status, copyright license, and source. − not sure which bot wouldd that be, but Special:Diff/398495519 just flew by my watchlist and there you go − 6 statements in 1 edit.
I’m really struggling to see the actual concern here. Edits are good, that means the changes are auditable − we can notice potential issues and notify the bot operator, who can fix-forward.
@Schlurcher: Thanks for your SDC work. Would it be possible to modify your bot to make fewer edits per file? It seems that the sheer volume may inconvenience some users. Thanks!

.jpg)
 Addendum, I suspect that it might be the coat of arms of the Regierungsbezirk Osnabrück, Hannover, but I can't find any online information about it. Are there good books on Prussian heraldry that covers municipal coats of arms I can use? --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 22:02, 1 February 2020 (UTC)
Addendum, I suspect that it might be the coat of arms of the Regierungsbezirk Osnabrück, Hannover, but I can't find any online information about it. Are there good books on Prussian heraldry that covers municipal coats of arms I can use? --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 22:02, 1 February 2020 (UTC)






.JPG)


 Done Sony α7 III
Done Sony α7 III TVlogic vfm-058W
TVlogic vfm-058W

.jpg)
.jpg)
.jpg)
.jpg)
.jpg)




 Keegan (WMF) (talk) 17:05, 12 February 2020 (UTC)
Keegan (WMF) (talk) 17:05, 12 February 2020 (UTC)
 Deaths from air pollution
Deaths from air pollution Sulphur dioxide emissions by region
Sulphur dioxide emissions by region Tobacco production
Tobacco production Population growth against age
Population growth against age Alcohol consumption by type in Italy
Alcohol consumption by type in Italy
_emissions_by_world_region,_OWID.svg)




 Support Good call. See also Commons:OTRS/Noticeboard#OTRS_&_Wikidata, where it turns out that wanted photographs of individuals with items on Wikidata (established 2012) are being rejected, unseen by the commons or Wikidata communities, by OTRS volunteers, based on a 2010 policy that is on a password-protected Wiki. (Note: this is already being discussed at two venues, including the page I link to; I don't mean to open a third). 14:40, 25 February 2020 (UTC)Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits
Support Good call. See also Commons:OTRS/Noticeboard#OTRS_&_Wikidata, where it turns out that wanted photographs of individuals with items on Wikidata (established 2012) are being rejected, unseen by the commons or Wikidata communities, by OTRS volunteers, based on a 2010 policy that is on a password-protected Wiki. (Note: this is already being discussed at two venues, including the page I link to; I don't mean to open a third). 14:40, 25 February 2020 (UTC)Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits Deleted, and @Eatcha: should stop wasting their time with it.--BevinKacon (talk) 11:33, 29 February 2020 (UTC)
Deleted, and @Eatcha: should stop wasting their time with it.--BevinKacon (talk) 11:33, 29 February 2020 (UTC)


 Info Because of this discussion and the other problems I created a proposal to restrict these beta tool to autopatrolled users. --GPSLeo (talk) 09:43, 16 February 2020 (UTC)
Info Because of this discussion and the other problems I created a proposal to restrict these beta tool to autopatrolled users. --GPSLeo (talk) 09:43, 16 February 2020 (UTC)
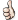 Brilliant, and for one dark hour in 2019, when I felt forced to log in for the so far first + last time since May 2016, how about limiting it to anything better than "patrol", e.g., "file mover" or "licence reviewer"? –84.46.52.151 07:24, 20 February 2020 (UTC)
Brilliant, and for one dark hour in 2019, when I felt forced to log in for the so far first + last time since May 2016, how about limiting it to anything better than "patrol", e.g., "file mover" or "licence reviewer"? –84.46.52.151 07:24, 20 February 2020 (UTC)
 Oppose What do you mean by "…until the developers have populated at least…"? Do you expect them to do it manually? Bots should run, interface for humans should not be available for general public (what is kinda strange because humans should be more "intelligent" than bots, but clearly they are not). Anyway, I agree with your opinion expressed here. --jdx Re: 09:55, 25 February 2020 (UTC)
Oppose What do you mean by "…until the developers have populated at least…"? Do you expect them to do it manually? Bots should run, interface for humans should not be available for general public (what is kinda strange because humans should be more "intelligent" than bots, but clearly they are not). Anyway, I agree with your opinion expressed here. --jdx Re: 09:55, 25 February 2020 (UTC)




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
_2014_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
_Signed_with_a_monogram._Oil_on_canvas.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
_head_-_iNaturalist.jpg){kind=link}
_-_iNaturalist_(photo_1).jpg){kind=link}
_-_iNaturalist_(photo_1).jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.png){kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}