Commons:Structured data/Archive/2014/Development


Product[edit]
Overview[edit]
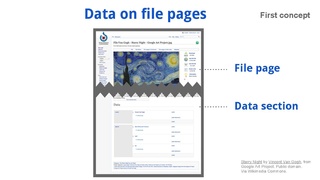


The actual 'product' that would be developed for Structured Data would look and feel similar to what exists today on Wikimedia Commons: the same basic information would be shown to the user, but it would be stored and edited in slightly different ways.
The current proposal is to display structured data in a new "Data section”, at the bottom of the "File: page" (see mockup to the right). This Data section would be used to migrate, view and edit structured data; the top sections of the current file page would continue to be used for displaying all file information, as well as to edit unstructured data.
During the first experimentation period, the same editing tools used on Wikidata.org would be adapted to make it easy to migrate and edit structured data on the "Data section" of the file pages on Commons. In future versions, new data editors could be developed, once reviewed, prototyped and tested by the community (see mockup to the right). In coming weeks, the development team can prepare first design mockups to help visualize how that might work, to make it easier for Commons users to provide feedback.
On the file description pages, we would still use templates to display the structured data from the data section. For example, the {{Information}} template would be changed to pull information like the contributor or description from the data section. Template parameters would only be used in rare cases to override the values from the media info page. Ideally, file description pages would in the end only contain a sole {{Information}} call with no parameters, but that wouldn't happen until all its file information is accessible in Wikibase.
For more product information, read on, or check the FAQ below, which will be expanded continuously.
Example[edit]
Here is an example of what metadata for a typical file could look like in a structured form:
- Title (Label): White Russian Hamster
- Description: The Djungarian hamster, also known as the Siberian hamster, Siberian
- dwarf hamster or Russian winter white dwarf hamster, is one of three species of hamster in the genus Phodopus.
- File name: Hamster ruso blanco.JPG
- File type: image/jpeg
- Resolution: 4,320 × 3,240 pixels
- Statements:
- Contributor: https://commons.wikimedia.org/User:Nanny99
- Role: Photographer
- License: http://creativecommons.org/license/CC-BY-SA-3.0
- Terms of use: BY-SA
- Topic: hamster
- Topic: pet
- Type of work: photograph
- Coordinate location: 52’31 N, 13’22 E
- Location: Berlin
Users[edit]
User Groups[edit]

Target users for Structured Data include these user groups:
- readers
- contributors
- editors/curators
- editors
- developers
- 3rd-party site users
- cultural institutions
This project is likely to impact everyone who uses media files on Commons and other Wikimedia sites. The goal is to support these user groups evenly, with an initial focus on Commons users, then contributors on Wikipedia, and then other sites.
Benefits[edit]
Here are some of the ways structured data can benefit users:
- offer a better user experience
- find relevant content
- offer metadata in more languages
- make it easier to re-use files in a license-compliant way
- drive curation and contributions
- support & create feedback loop for GLAMs
User Stories[edit]
For the first releases, we propose to focus on these key user stories:
- View structured data
- View integrated file information
- Find all the data about this file
- Learn what the data section is for
- View file information in my language
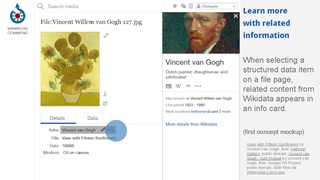
- View related information in the data section
- View related information at the top of the file page
- View related information in an info card
- Edit structured data
- Edit structured data in the data section
- Edit file information with a hybrid editor
- Learn how to edit structured data
- Edit a description in my language
- Edit a contributor for a file
- Edit a license for a file
- Edit a category for a file
- Review structured data edits
- Migrate to structured data
- Migrate single data for a single file
- Migrate multiple data for a single file
- Migrate multiple data for multiple files
- Search with structured data
- Search by single topic
- Search by multiple topics
- Search by category
- Search by media type
- etc.
- Upload with structured data
- Upload files with structured data
- Upload collections of files with structured data
For more details on stories above, check the User Stories section.
Design[edit]

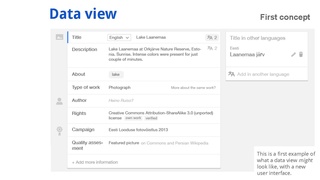
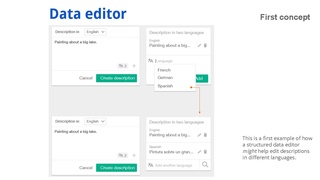

Here are some highlights of the dedicated Design page , which focuses on design goals to understand issues, propose solutions and validate them for the Structured Data project.
Scenarios[edit]
In order to identify the needs of different kinds of users, we created some first scenarios. For the current stage of this investigating scenarios related to Commons curators, because their expertise in managing file information will help us to iterate on how to present and edit information for all kinds of media files. In addition, activities from other users depend on structured data to exist and being editable. Allowing search based on structured data (as a great improvement as it is) has little value if files lack structured data, and advanced editing (provide information as you upload, or manage a high amount of files) will build on the solutions for the more basic editing needs.
A compete list of the scenarios explored is available. For Commons curators we have focused so far on the following ones:
- Classification. the user goes through a list of recent uploads and classifies them by adding and correcting their topics/categories.
- Review copyright status. the user checks that licenses and copyright is correct for a file. If needed, the user indicates that the license for a file is not correct, add additional information, or mark the file as a copyright violation.
- Add multilingual information. The user goes through a list of recent uploads and adds file descriptions in different languages when some of the user native languages are missing.
- Add location information. The user provides missing geographic coordinates for pictures of monuments that lack such information from a list of recent uploads.
- Complement information of a collection. After a museum uploaded many paintings by Van Gogh from the same museum, the user wants to add specific information to each of them: a more detailed description, topics, and license information.
- Look for missing information. Search a museum collection of cubist paintings that have the author information missing, and adds their author.
- Topic creation. The user creates a new topic about a conference for which images are expected and shares it with the conference organizers so that participants can upload pictures to it.
Design approaches[edit]
As a first step, we propose to explore ideas about presenting and editing structured data for media files. The patterns proposed below are generic (e.g., multilingual text strings can be used in many different fields when describing a file).
We are looking specifically at these design challenges:
- Information complexity and progressive disclosure
- Referencing entities
- Rich multilingual information
- Flexible types
- Navigation structures
- Getting started with a simple edit
- Considerations for specific pieces of information
Design process[edit]
We propose an iterative design process that includes these steps:
- planning: identify first workflows we need to support (view, edit and migrate data)
- design: prepare first mockups to explore possible design solutions
- research: test mockups with users, to validate designs
- iterate: rince and repeat, as needed
Design research[edit]
Here are some questions we might ask users in our first research studies:
- Do you understand what structured data means and what its benefits are?
- Can you tell when a data property on a file page has been structured?
- Can you find the structured data section on the file page?
- Can you find the information you need in this data section?
- Can you find which fields need to be edited?
- Can you tell how to edit structured data?
- Can you tell how to migrate data in structured format?
For more details, check the Design page.
Technology[edit]
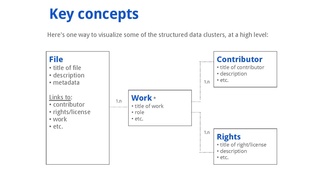
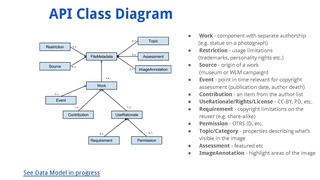
Data model[edit]
One of the challenges of this project is to define a data model that does not limit the scope of items to be stored and is compatible with external tools, while avoiding redundancy and confusion.
Throughout the planning phases, the development teams will collaborate with community members to determine which data are most needed to support their various workflows. The goal is to collectively develop a comprehensive list of basic data, to make sure that all important items are accounted for.
The data model is likely to include these key elements for each file:
- title
- description
- work
- contributor
- role
- rights/licenses
- restrictions
- category
- topics
Some basic concepts are being discussed as possible building blocks for the data model. For example, a media file can include one or more works, each work can have one or more contributors, as well as one or more rights or licenses. This high level organizing principle could support a wide range of use cases that will need to be discussed further.
Components[edit]
Some of the first code modules the development team might work on are:
- high-level API
- data back-end storage
- data section on file page
- edit tool on file page
- review tools + processes
- basic search
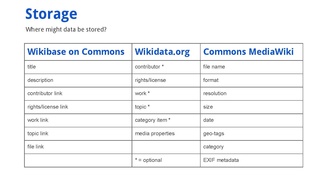
Storage[edit]

Where might data be stored? Below is a first idea of how things could be implemented.
- Wikibase on Commons
- title
- description
- work link
- contributor link
- right/license link
- topic link
- file link
- Wikidata.org
- contributor
- right/license
- work
- topic
- category
- media properties
- Commons MediaWiki
- file name
- format
- resolution
- size
- date
- geo-tags
- category
- EXIF metadata
Research[edit]
Here are some of the research metrics we are considering to track the effectiveness of this project (for more details, check this Research page).
- Measures of success
- # files used on WMF-hosted projects
- # uncategorized files on Commons
- # (successful) search queries for media files
- # views per file
- Measures of progress
- # files with data properties
- % new uploads with structured data
- % template calls without parameters
We are discussing other metrics to track success and progress on this Research page. We plan to host community discussions to evaluate and select key metrics for this project.
Rights[edit]

Media files on commons currently use a wide range of templates to track rights, licenses and restrictions. These templates preserve a significant amount of valuable information, such public domain assessments, Creative Commons license permissions, and warnings about trademarks or other topics.
Structured Data can help:
- make rights, licenses and restrictions information more accessible
- provide relevant information to users who assess and review a work's public domain status
- determine the information necessary to comply with the terms of a license
- encourage re-use by third parties under proper terms
We plan to develop a model of significant rights and restrictions information that can be initially populated with data gathered through the Metadata Cleanup project. Given the complexity of the current rights and permissions information, there will be some challenges ahead to develop a standard model. During discussions at the Structured Data Bootcamp, we developed an initial framework for rights and restrictions information. This framework will be improved through the experimental phase of this project and discussions with the community.
Roadmap[edit]
Here are some of the stages the development team is considering for this work, in outline form (see roadmap page for more details). All goals below are tentative and for discussion purposes only.
Stage 1[edit]
- product planning with teams & communities
- community discussions
- user stories / workflow
- design / user research
- first data model
- data migration
- first high-level API prototype
- code cleanup
- obtain baseline metrics
Stage 2[edit]
- more community discussions
- updated goals, data model, functions
- detailed specifications
- updated designs
- first prototypes
- develop key components
- integrate them into existing systems
- user testing on prototype site
- small experiments
- data migration
- updated designs and spec
- updated product plan
Stage 3[edit]
- improve code modules
- develop new code modules
- more user testing on prototype
- deploy code on Commons
- community discussions / training
- more user testing on Commons
- start data migration on Commons
- gradual release process
- updated designs and spec
- more user testing with wider base
- wide promotion about the new release
- updated product plan
In coming months, we will aim to break down and estimate these tasks, so we can scope out this project more accurately. At this stage, we do not have enough information to propose a realistic timeline, due to the complexity of the tasks and their interdependencies. This preliminary roadmap is likely to go through several more drafts, based on team and community feedback.
For more details, check the Roadmap page.
Links[edit]
As activity on this project increases in the next few weeks, shared notepads will be used to quickly gather initial findings, then they will be turned into more structured wiki pages like this one. Here are a few working documents currently used for planning:
- Structured Data Slides (from Wikimania roundtable discussion)
- Roundtable Notepad (from Wikimania roundtable discussion)
- User stories
- Structured data examples
- Structured Data List
- Multimedia data API
- Wikidata for Media Info
- Structured Data Wall
- Wikidata: Wikimedia Commons
- Commons Wikidata Roadmap
- Request for comment: Structured Commons
- Wikidata Model