File:Lotka law for the 15 most populated categories on arXiv (2023-07).svg

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Original file (SVG file, nominally 1,800 × 1,440 pixels, file size: 351 KB)
Captions
Captions
Summary
[edit].svg&action=edit§ion=1){kind=link}
| Description |
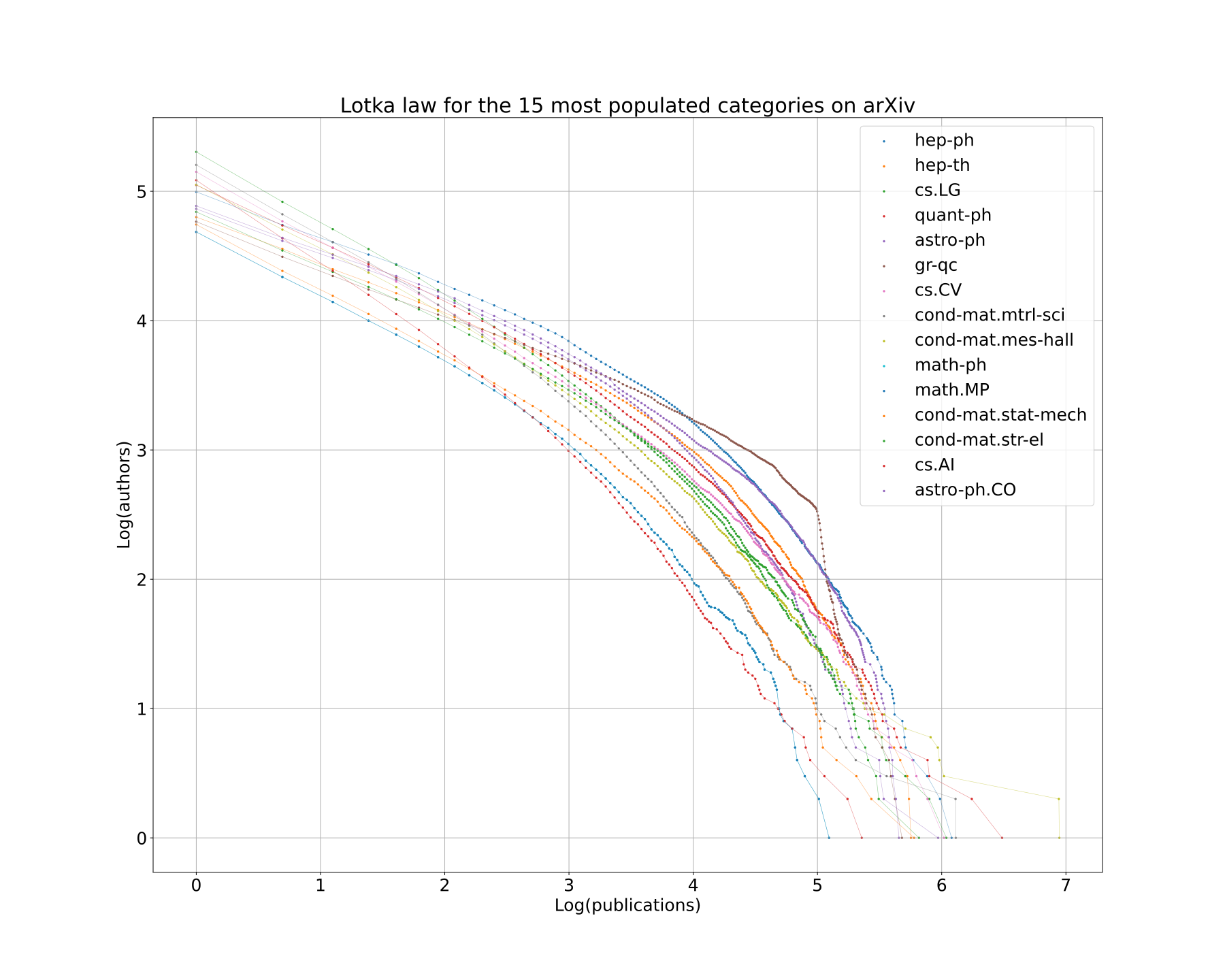
English: Lotka law for the 15 most populated categories on arXiv, as of 2023-07.
It is a log-log plot. The x-axis is the number of publications, and the y-axis is the number of authors with at least that many publications. Data from https://www.kaggle.com/datasets/Cornell-University/arxiv ```python import pandas as pd import json
categories_list = [] authors_parsed_list = []
with open('arxiv-metadata-oai-snapshot.json', 'r') as file: for line in file:
# Parse the JSON string
paper = json.loads(line)
# Extract the "categories" and "authors_parsed" fields
categories = paper.get("categories", "")
authors_parsed = paper.get("authors_parsed", [])
# Split categories string into list and store
categories_list.append(categories.split())
# Store the authors_parsed data
authors_parsed_list.append(authors_parsed)
df = pd.DataFrame({"categories": categories_list, "authors_parsed": authors_parsed_list}) categories_list = [category for categories in df['categories'] for category in categories] unique_categories = set(categories_list) from collections import Counter
categories_list = [category for categories in df['categories'] for category in categories]
category_counts = Counter(categories_list)
sorted_categories = sorted(category_counts.items(), key=lambda x: x[1], reverse=True)
for category, count in sorted_categories: print(f"{category}: {count}")
import pandas as pd def count_authors(df, category_list): counter = {}
# Filter rows that match the specified categories mask = df['categories'].apply(lambda x: any(category in x for category in category_list)) filtered_df = df[mask] # Flatten the authors_parsed column flattened_authors = [author for authors in filtered_df['authors_parsed'] for author in authors] # Count the occurrences of each author
for author in flattened_authors:
author_name = author[1] + ' ' + author[0]
counter[author_name] = counter.get(author_name, 0) + 1
return counter
categories_list = [category for categories in df['categories'] for category in categories]
category_counts = Counter(categories_list)
sorted_categories = sorted(category_counts.items(), key=lambda x: x[1], reverse=True)
plt.rcParams.update({'font.size': 20}) fig, axs = plt.subplots(figsize=(10, 8)) n_categories = 15 for category, _ in sorted_categories[:n_categories]: result = count_authors(df, [category]) data = pd.DataFrame(np.log(list(result.values())), columns=['x'])["x"] magnitudes = data.sort_values(ascending=False) unique_magnitudes = magnitudes.unique() print(category) # Compute reverse cumulative count of earthquakes for all data cumulative_counts = magnitudes.value_counts().sort_index(ascending=False).cumsum().sort_index() axs.scatter(cumulative_counts.index, np.log10(cumulative_counts.values), label=category, s=3) axs.legend() axs.grid() axs.set_title(f"Lotka law for the {n_categories} most populated categories on arXiv") axs.set_xlabel("Log(publications)") axs.set_ylabel("Log(authors)") plt.show() plt.savefig("out.svg") ``` |
| Date | |
| Source | Own work |
| Author | Cosmia Nebula |
Licensing
[edit].svg&action=edit§ion=2){kind=link}
- You are free:
- to share – to copy, distribute and transmit the work
- to remix – to adapt the work
- Under the following conditions:
- attribution – You must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use.
- share alike – If you remix, transform, or build upon the material, you must distribute your contributions under the same or compatible license as the original.
File history
Click on a date/time to view the file as it appeared at that time.
| Date/Time | Thumbnail | Dimensions | User | Comment | |
|---|---|---|---|---|---|
| current | 01:14, 18 July 2023 | | 1,800 × 1,440 (351 KB) | Cosmia Nebula (talk | contribs) | Uploaded own work with UploadWizard |
You cannot overwrite this file.
File usage on Commons
There are no pages that use this file.
File usage on other wikis
The following other wikis use this file:
- Usage on en.wikipedia.org
.svg&oldid=811931451){kind=link}